powered by 
Das JPEG-Format (Joint Photographic Experts Group) ist ein weit verbreitetes Bildformat, das hauptsächlich für die Komprimierung von Fotografien und realistischen Bildern verwendet wird. Es wurde in den frühen 1990er Jahren entwickelt und bietet eine effiziente Methode zur Reduzierung der Dateigröße von Bildern, während gleichzeitig eine akzeptable Bildqualität beibehalten wird. JPEG verwendet eine verlustbehaftete Komprimierungstechnik, bei der bestimmte Bildinformationen entfernt werden, um die Dateigröße zu verringern. Dies führt zu einer gewissen Qualitätsminderung, die jedoch oft nicht sichtbar ist, insbesondere bei höheren Qualitätsstufen.
Dieser Artikel soll dir helfen, einen JPEG-Decoder zu implementieren. Dafür ist es wichtig, zunächst einige Grundlagen zu verstehen:
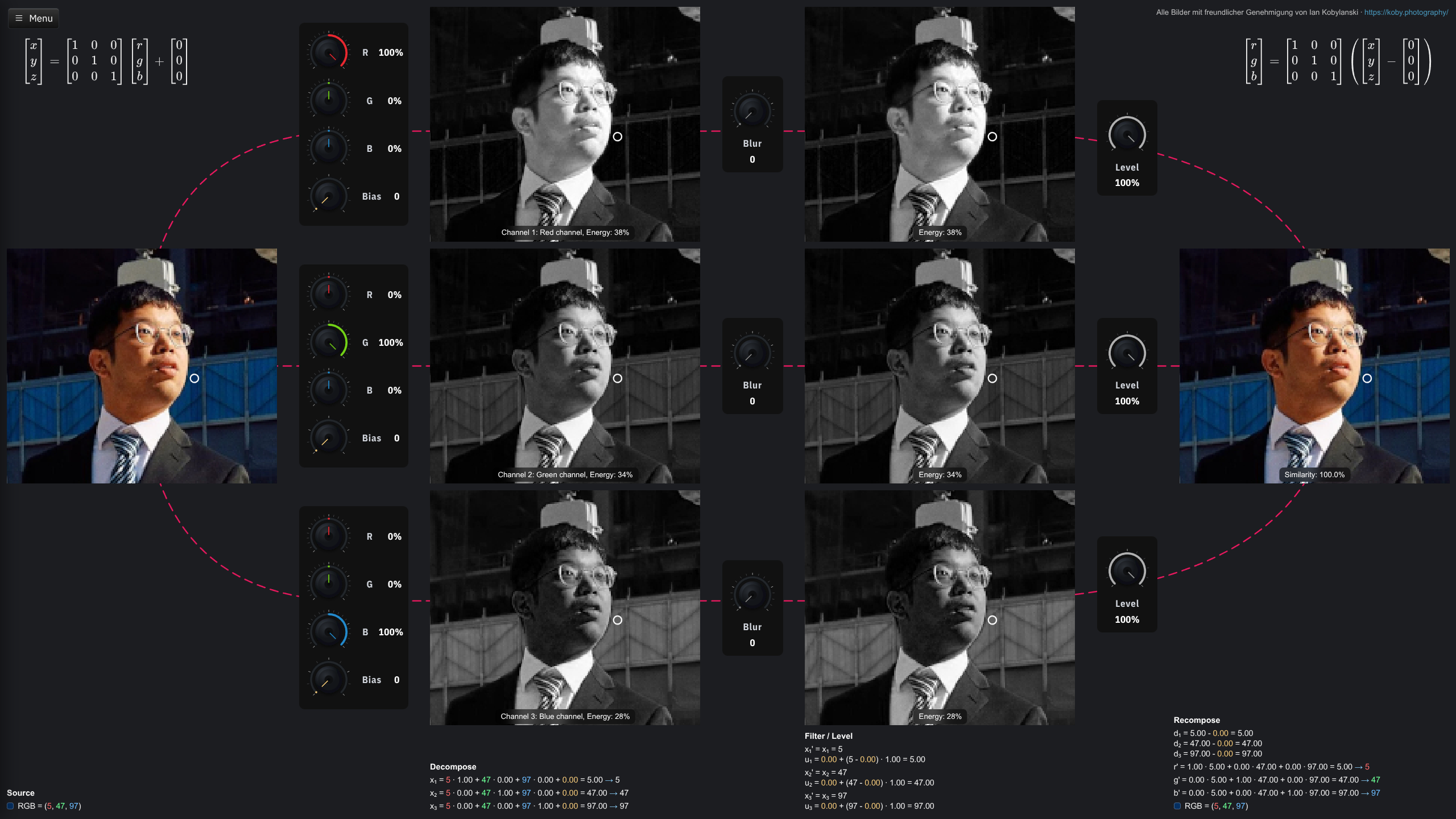
 Farbräume
Farbräume
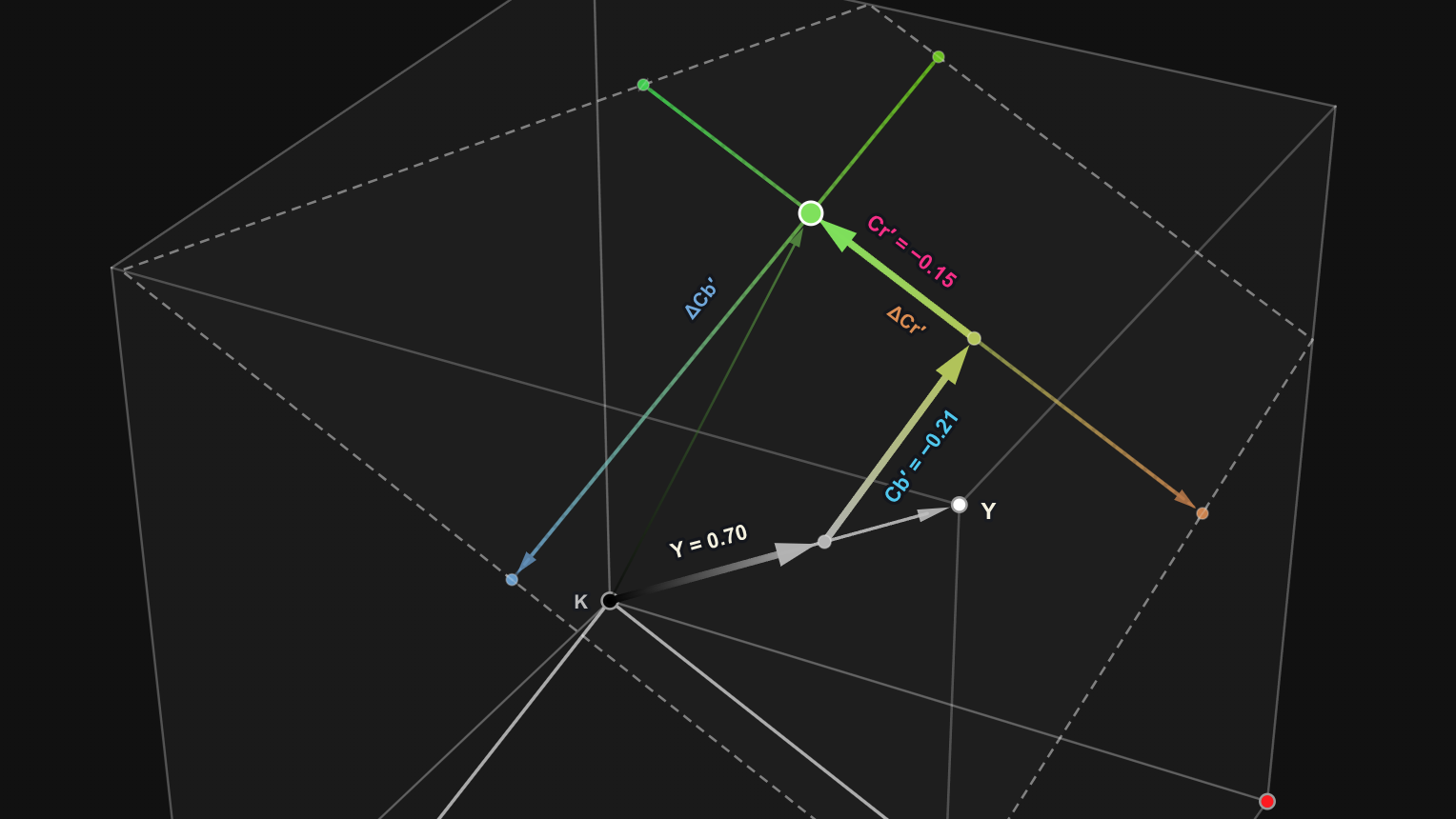
 Trennung von Helligkeit und Farbe
Trennung von Helligkeit und Farbe
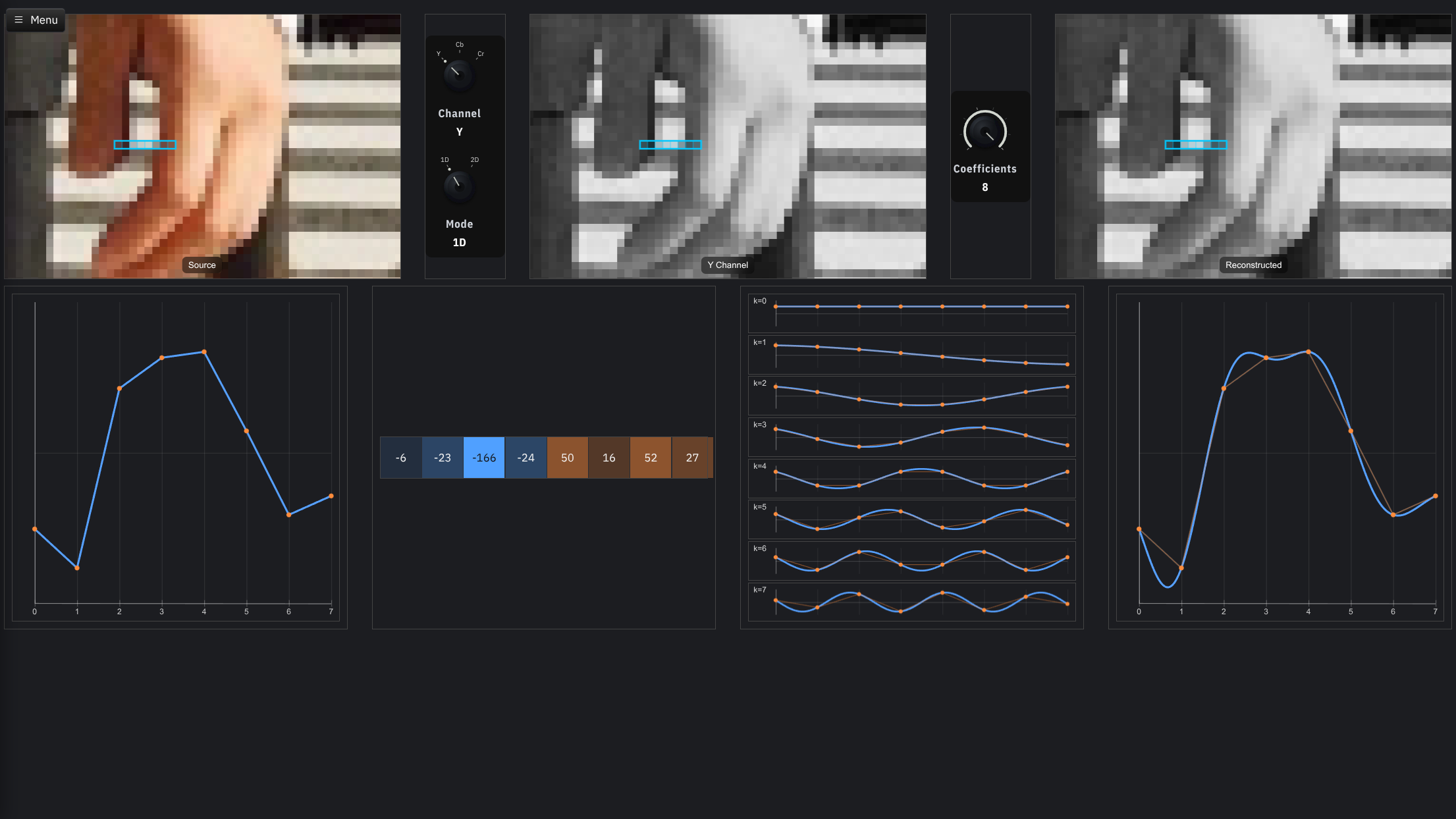 Diskrete Kosinustransformation (DCT)
Diskrete Kosinustransformation (DCT)
Um eine JPEG-Datei zu decodieren, musst du die folgenden Schritte durchführen:
Der vollständige JPEG-Standard ist sehr umfangreich und komplex. Wir fassen deshalb hier alle relevanten Informationen zusammen, die du für die Implementierung eines Baseline-JPEG-Decoders benötigst.
Wir beginnen mit den Markern und Segmenten, die die Struktur einer JPEG-Datei definieren, und gehen dann Schritt für Schritt durch die Decodierung der Bilddaten.
Marker sind spezielle 16-Bit-Sequenzen, die bestimmte Abschnitte eines JPEG-Bildes kennzeichnen. Sie beginnen immer mit 0xFF, gefolgt von einem weiteren Byte, das den Typ des Markers angibt. Einige Marker stehen für sich allein und beinhalten keine Daten, während andere Marker von einer 16-Bit-Länge gefolgt werden, die die Anzahl der nachfolgenden Datenbytes angibt (inkl. der 2 Bytes für die Länge selbst). Hier ist eine Übersicht über die wichtigsten Marker (dabei werden Marker ohne Daten mit einem Sternchen (*) gekennzeichnet):
| Marker | Name | Beschreibung | |
|---|---|---|---|
0xFFD8 |
SOI* |
Start of Image | Markiert den Beginn eines JPEG-Bildes. |
0xFFDB |
DQT |
Define Quantization Table | Definiert eine oder mehrere Quantisierungstabellen. |
0xFFC0 |
SOF0 |
Start of Frame (Baseline DCT) | Definiert die Bildgröße, die Anzahl der Komponenten und die Präzision der Bilddaten. |
0xFFC4 |
DHT |
Define Huffman Table | Definiert eine oder mehrere Huffman-Tabellen. |
0xFFDA |
SOS |
Start of Scan | Markiert den Beginn der komprimierten Bilddaten. |
0xFFD9 |
EOI* |
End of Image | Markiert das Ende eines JPEG-Bildes. |
Der SOI-Marker (0xFFD8) markiert den Beginn eines JPEG-Bildes. Er besteht aus zwei Bytes und enthält keine weiteren Daten. Ein gültiges JPEG-Bild muss mit diesem Marker beginnen.
7 6 5 4 3 2 1 0 Field Name Type
+---------------+
0 | | Marker (FFD8) Word
+- -+
1 | |
+---------------+
Beispiel:
00000000 ff d8 ff e0 00 10 4a 46 49 46 00 01 01 01 01 2c |......JFIF.....,|
Der SOI-Marker steht am Anfang der Datei. Sollte er fehlen, beende dein Programm mit einer Fehlermeldung. Gleich im Anschluss an den SOI-Marker folgt oft ein APP0-Segment (0xFFE0), das Metadaten enthält. Wir überspringen es mit Hilfe der Segmentlänge, da es für uns nicht relevant ist.
Die Beispiele beziehen sich alle auf die Datei 44-baseline.jpg, die du zum Testen deiner Implementation verwenden kannst.
Im DQT-Segment werden Quantisierungstabellen definiert. Es gibt 4 mögliche Slots für diese Tabellen (0 bis 3), die jeweils 64 Werte enthalten. Die 64 Werte sind in der Zig-Zag-Reihenfolge abgespeichert.
7 6 5 4 3 2 1 0 Field Name Type
+---------------+
0 | | Marker (FFDB) Word
+- -+
1 | |
+---------------+
2 | | Segment Length Word
+- -+
3 | |
+---------------+
4 | Pq | Tq | [Packed Fields] See below
+---------------+
5 | | Quantization Table Values 64 Bytes
+- . . . . -+
68 | |
+---------------+
[Packed Fields] = Pq: Precision (0 = 8-bit, 1 = 16-bit) 4 Bits
Tq: Table Identifier (0–3) 4 Bits
Beispiel:
00000010 01 2c 00 00 ff db 00 43 00 05 03 04 04 04 03 05 |.,.....C........| 00000020 04 04 04 05 05 05 06 07 0c 08 07 07 07 07 0f 0b |................| 00000030 0b 09 0c 11 0f 12 12 11 0f 11 11 13 16 1c 17 13 |................| 00000040 14 1a 15 11 11 18 21 18 1a 1d 1d 1f 1f 1f 13 17 |......!.........| 00000050 22 24 22 1e 24 1c 1e 1f 1e ff db 00 43 01 05 05 |"$".$.......C...|
FF DB |
DQT-Marker |
00 43 |
Segmentlänge (0x43 = 67 Bytes)
Es kann vorkommen, dass in einem DQT-Segment mehrere Quantisierungstabellen definiert werden. Du erkennst dies daran, dass die Segmentlänge größer als erwartet ist. In diesem Fall wiederholt sich die Struktur ab Offset 4. |
00 |
Pq = 0 (8-Bit-Werte), Tq = 0 (Slot 0)
Du kannst für deinen Decoder davon ausgehen, dass Pq immer 0 ist, wir also 8-Bit-Werte einlesen können. Sollte Pq einen anderen Wert haben, beende dein Programm mit einer Fehlermeldung. |
05 03 04 04 ... |
64 Werte der Quantisierungstabelle
Speichere die Werte in dem entsprechenden Slot (Tq) ab, damit du sie später für die Dequantisierung verwenden kannst. |
Im SOF0-Segment (Start of Frame, Baseline DCT) werden die Bildgröße, die Anzahl der Komponenten und die Präzision der Bilddaten definiert. Es enthält auch Informationen über die Subsampling-Methode, die für die Chroma-Kanäle verwendet wird.
7 6 5 4 3 2 1 0 Field Name Type
+---------------+
0 | | Marker (FFC0) Word
+- -+
1 | |
+---------------+
2 | | Segment Length Word
+- -+
3 | |
+---------------+
4 | P | Sample Precision Byte
+---------------+
5 | Y | Number of Lines Word
+- -+
6 | |
+---------------+
7 | X | Number of Samples/Line Word
+- -+
8 | |
+---------------+
9 | Nf | Number of Image Components Byte
+---------------+
(for each image component:)
+---------------+
10 | Ci | Component Identifier Byte
+---------------+
11 | Hi | Vi | [Packed Fields] See below
+---------------+
12 | Tqi | Quantization Table Selector Byte
+---------------+
[Packed Fields] = Hi: Horizontal Sampling Factor 4 Bits
Vi: Vertical Sampling Factor 4 Bits
Beispiel:
00000090 1e 1e 1e 1e 1e 1e 1e 1e 1e 1e 1e 1e 1e 1e ff c0 |................| 000000a0 00 11 08 02 9b 03 e8 03 01 22 00 02 11 01 03 11 |........."......| 000000b0 01 ff c4 00 1f 00 00 01 05 01 01 01 01 01 01 00 |................|
FF C0 |
SOF0-Marker
Zusätzlich zum SOF0-Marker gibt es noch weitere SOF-Marker (SOF1, SOF2, ...), die für verschiedene JPEG-Varianten verwendet werden. Für unseren Baseline-JPEG-Decoder kannst du davon ausgehen, dass nur der SOF0-Marker verwendet wird. |
00 11 |
Segmentlänge (0x11 = 17 Bytes) |
08 |
Sample Precision (8 Bit)
Du kannst für deinen Decoder davon ausgehen, dass dieser Wert immer 8 ist. Sollte er einen anderen Wert haben, beende dein Programm mit einer Fehlermeldung. |
02 9B |
Anzahl der Zeilen (0x29b = 667)
Dieser Wert beschreibt die Höhe des Bildes in Pixeln. |
03 E8 |
Anzahl der Samples pro Zeile (0x3e8 = 1000)
Dieser Wert beschreibt die Breite des Bildes in Pixeln. |
03 |
Anzahl der Komponenten (3)
Du kannst für deinen Decoder davon ausgehen, dass dieser Wert immer 3 ist und für die drei Komponenten Y, Cb und Cr steht. Sollte er einen anderen Wert haben, beende dein Programm mit einer Fehlermeldung. |
01 22 00
|
Komponente 1 (Y), 2:2 Subsampling, Quantization Table 0 |
02 11 01
|
Komponente 2 (Cb), 1:1 Subsampling, Quantization Table 1 |
03 11 01
|
Komponente 3 (Cr), 1:1 Subsampling, Quantization Table 1 |
In diesem Beispiel siehst du, dass die Y-Komponente (Helligkeit) mit einem 2:2-Subsampling codiert ist, während die Cb- und Cr-Komponenten (Farbinformationen) mit einem 1:1-Subsampling codiert sind. Im JPEG-Jargon spricht man von einer Minimal Coding Unit (MCU), die in diesem Fall aus 4 Y-Blöcken, 1 Cb-Block und 1 Cr-Block besteht. Das bedeutet, dass für jede MCU 4 Blöcke der Y-Komponente und jeweils 1 Block der Cb- und Cr-Komponenten codiert werden: die Auflösung der Chroma-Komponenten ist also halb so hoch wie die der Luma-Komponente in beiden Dimensionen.
Im DHT-Segment werden Huffman-Tabellen definiert, die wir für die Decodierung der komprimierten Bilddaten benötigen. Dabei wird in DC- und AC-Tabellen unterschieden: DC-Tabellen codieren die Differenzen der DC-Koeffizienten, während AC-Tabellen die AC-Koeffizienten codieren. Es gibt 4 mögliche Slots für DC-Tabellen (0 bis 3) und 4 mögliche Slots für AC-Tabellen (0 bis 3). Jede Tabelle besteht aus 16 Bytes, die die Anzahl der Codes für jede Code-Länge von 1 bis 16 angeben, gefolgt von den Symbolen, die diesen Codes zugeordnet sind.
7 6 5 4 3 2 1 0 Field Name Type
+---------------+
0 | | Marker (FFC4) Word
+- -+
1 | |
+---------------+
2 | | Segment Length Word
+- -+
3 | |
+---------------+
4 | Tc | Th | [Packed Fields] See below
+---------------+
5 | L1 | Number of Codes of Length 1 Byte
+- . . . . -+
20 | L16 | Number of Codes of Length 16 Byte
+---------------+
21 | V1 | First Symbol Byte
+- . . . . -+
| Vn | Last Symbol Byte
+---------------+
[Packed Fields] = Tc: Table Class (0 = DC, 1 = AC) 4 Bits
Th: Table Identifier (0–3) 4 Bits
000000b0 01 ff c4 00 1f 00 00 01 05 01 01 01 01 01 01 00 |................| 000000c0 00 00 00 00 00 00 00 01 02 03 04 05 06 07 08 09 |................| 000000d0 0a 0b ff c4 00 b5 10 00 02 01 03 03 02 04 03 05 |................|
FF C4 |
DHT-Marker |
00 1F |
Segmentlänge (0x1f = 31 Bytes)
Es kann vorkommen, dass in einem DHT-Segment mehrere Huffman-Tabellen definiert werden. Du erkennst dies daran, dass die Segmentlänge größer als erwartet ist. In diesem Fall wiederholt sich die Struktur ab Offset 4. |
00 |
Tc = 0 (DC-Tabelle), Th = 0 (Slot 0)
Dieser Huffman-Baum ist für DC-Slot 0 bestimmt und wird später benötigt werden. |
00 01
05 01
01 01
01 01
01 00
00 00
00 00
00 00
|
Anzahl der Codes pro Code-Länge für die DC-Tabelle im Slot 0
Diese Werte geben an, wie viele Codes es mit einer bestimmten Länge gibt. In diesem Beispiel gibt es 0 Codes mit der Länge 1, 1 Code mit der Länge 2, 5 Codes mit der Länge 3 sowie jeweils 1 Code mit den Längen 4, 5, 6, 7, 8 und 9 – insgesamt also 12 Codes, deren Symbole nun folgen. |
00 01
02 03
04 05
06 07
08 09
0a 0b
|
Symbole für die DC-Tabelle im Slot 0
Diese Werte sind die Symbole, die den Codes zugeordnet werden. Das erste Symbol (0x00) wird dem einzigen Code mit der Länge 2 zugeordnet, die nächsten 5 Symbole (0x01 bis 0x05) werden den 5 Codes mit der Länge 3 zugeordnet, und so weiter. |
Implementierungshinweis:
Für einen JPEG-Decoder benötigst du keinen tatsächlichen Huffman-Baum. Es reicht, für jede Codelänge einen Bereich von Codes zu berechnen, der dieser Länge entspricht, und die Symbole in der richtigen Reihenfolge diesen Codes zuzuordnen.
Wir benötigen die folgenden Arrays:
min_code: Ein Array, das für jede Codelänge den kleinsten Code dieser Länge enthält.max_code: Ein Array, das für jede Codelänge den größten Code dieser Länge enthält.val_ptr: Ein Array, das für jede Codelänge den Index des ersten Symbols dieser Länge enthält.huffval: Ein Array, das die Symbole enthält, sortiert nach der Reihenfolge der Codes.In unserem Beispiel würden sich diese Arrays wie folgt füllen:
| length | min_code | max_code | (valid codes) | val_ptr |
|---|---|---|---|---|
| 1 | – | – | – | – |
| 2 | 0 | 0 | 00 | 0 |
| 3 | 2 | 6 | 010, 011, 100, 101, 110 | 1 |
| 4 | 14 | 14 | 1110 | 6 |
| 5 | 30 | 30 | 11110 | 7 |
| 6 | 62 | 62 | 111110 | 8 |
| 7 | 126 | 126 | 1111110 | 9 |
| 8 | 254 | 254 | 11111110 | 10 |
| 9 | 510 | 510 | 111111110 | 11 |
| 10 | – | – | – | – |
| ... | ||||
Die Werte für huffval können direkt aus den Symbolen im DHT-Segment übernommen werden, da sie bereits in der richtigen Reihenfolge vorliegen. Es ergibt sich also folgende Zuordnung:
| Code | 00 | 010 | 011 | 100 | 101 | 110 | 1110 | 11110 | 111110 | 1111110 | 11111110 | 111111110 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
Im Decoder müssen wir später »nur noch« die Bits solange einzeln einlesen, bis wir einen gültigen Code erkennen und das entsprechende Symbol ermitteln können.
Ein weiteres Beispiel:
In diesem Beispiel wird eine AC-Tabelle im Slot 0 definiert, die deutlich mehr Codes enthält als die vorherige DC-Tabelle. Wir benötigen sie später für die Decodierung der AC-Koeffizienten.
000000d0 0a 0b ff c4 00 b5 10 00 02 01 03 03 02 04 03 05 |................| 000000e0 05 04 04 00 00 01 7d 01 02 03 00 04 11 05 12 21 |......}........!| 000000f0 31 41 06 13 51 61 07 22 71 14 32 81 91 a1 08 23 |1A..Qa."q.2....#| 00000100 42 b1 c1 15 52 d1 f0 24 33 62 72 82 09 0a 16 17 |B...R..$3br.....| 00000110 18 19 1a 25 26 27 28 29 2a 34 35 36 37 38 39 3a |...%&'()*456789:| 00000120 43 44 45 46 47 48 49 4a 53 54 55 56 57 58 59 5a |CDEFGHIJSTUVWXYZ| 00000130 63 64 65 66 67 68 69 6a 73 74 75 76 77 78 79 7a |cdefghijstuvwxyz| 00000140 83 84 85 86 87 88 89 8a 92 93 94 95 96 97 98 99 |................| 00000150 9a a2 a3 a4 a5 a6 a7 a8 a9 aa b2 b3 b4 b5 b6 b7 |................| 00000160 b8 b9 ba c2 c3 c4 c5 c6 c7 c8 c9 ca d2 d3 d4 d5 |................| 00000170 d6 d7 d8 d9 da e1 e2 e3 e4 e5 e6 e7 e8 e9 ea f1 |................| 00000180 f2 f3 f4 f5 f6 f7 f8 f9 fa ff c4 00 1f 01 00 03 |................|
Der SOS-Marker (Start of Scan) markiert den Beginn der komprimierten Bilddaten. Er enthält Informationen über die Anzahl der Komponenten im Scan sowie die zu verwendenden Huffman-Tabellen.
7 6 5 4 3 2 1 0 Field Name Type
+---------------+
0 | | Marker (FFDA) Word
+- -+
1 | |
+---------------+
2 | | Segment Length Word
+- -+
3 | |
+---------------+
4 | Ns | Number of Image Components in Scan Byte
+---------------+
(for each image component in scan:)
+---------------+
5 | Cs | Scan Component Selector Byte
+---------------+
6 | Td | Ta | [Packed Fields] See below
+---------------+
[Packed Fields] = Td: DC Huffman Table Selector 4 Bits
Ta: AC Huffman Table Selector 4 Bits
(at the end:)
+---------------+
7 | Ss | Start of Spectral Selection Byte
+---------------+
8 | Se | End of Spectral Selection Byte
+---------------+
9 | Ah | Al | Successive Approximation Byte
+---------------+
[Packed Fields] = Ah: Successive Approximation High 4 Bits
Al: Successive Approximation Low 4 Bits
Beispiel:
00000260 fa ff da 00 0c 03 01 00 02 11 03 11 00 3f 00 f0 |.............?..| 00000270 7b 9d 26 64 7c c4 d9 52 7e e9 ed 59 b3 44 23 60 |{.&d|..R~..Y.D#`| 00000280 92 2e c6 3d 33 5d f5 c5 96 d2 44 67 38 ec 45 72 |...=3]....Dg8.Er|
FF DA |
SOS-Marker |
00 0C |
Segmentlänge (0x0c = 12 Bytes) |
03 |
Anzahl der Komponenten im Scan (3)
Du kannst für deinen Decoder davon ausgehen, dass dieser Wert immer 3 ist und für die drei Komponenten Y, Cb und Cr steht. Sollte er einen anderen Wert haben, beende dein Programm mit einer Fehlermeldung. |
01 00
02 11
03 11
|
Auswahl der Huffman-Tabellen
Für jede der drei Komponenten Y, Cb und Cr wird angegeben, welche DC- und AC-Huffman-Tabelle verwendet werden soll. In diesem Beispiel wird für die Y-Komponente DC-Tabelle 0 und AC-Tabelle 0 verwendet, während für die Cb- und Cr-Komponenten jeweils DC-Tabelle 1 und AC-Tabelle 1 verwendet wird. |
00
3f
00
|
Parameter für Progressive JPEGs
In komplexeren JPEG-Varianten können Teile der Bilddaten nach und nach codiert werden. Dies war vor allem früher wichtig, als die Übertragung von Bildern über das Internet noch sehr langsam war. Du kannst für deinen Decoder davon ausgehen, dass diese Werte immer 0x00, 0x3f und 0x00 sind. Sollte dies nicht der Fall sein, beende dein Programm mit einer Fehlermeldung. |
Direkt hinter dem SOS-Segment beginnen die komprimierten Bilddaten:
00000260 fa ff da 00 0c 03 01 00 02 11 03 11 00 3f 00 f0 |.............?..| 00000270 7b 9d 26 64 7c c4 d9 52 7e e9 ed 59 b3 44 23 60 |{.&d|..R~..Y.D#`| 00000280 92 2e c6 3d 33 5d f5 c5 96 d2 44 67 38 ec 45 72 |...=3]....Dg8.Er|
Dabei wird das Bild MCU-weise codiert. In unserem Beispiel haben wir eine MCU-Größe von 16x16 Pixeln, bestehend aus 4 Blöcken der Y-Komponente (jeweils 8x8 Pixel), 1 Block der Cb-Komponente (8x8 Pixel) und 1 Block der Cr-Komponente (8x8 Pixel), also folgende Reihenfolge: Y0, Y1, Y2, Y3, Cb0, Cr0. Wir müssen demnach insgesamt sechs 8x8-Pixel-Blöcke decodieren, um eine MCU von 16x16 Pixeln zu erhalten.
In jedem Block wird zuerst der DC-Koeffizient decodiert, indem die entsprechenden Bits aus der Datei gelesen werden. Wir verwenden in diesem Beispiel die folgende DC-Tabelle in Slot 0, die wir vorher aus dem ersten DHT-Segment erstellt haben:
| Code | 00 | 010 | 011 | 100 | 101 | 110 | 1110 | 11110 | 111110 | 1111110 | 11111110 | 111111110 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
Nehmen wir die ersten beiden Bytes F0 7B und betrachten sie als Bits:
11110000 01111011
Den ersten Code, den wir finden ist 11110:
11110 000 01111011
Der Code 11110 entspricht dem Symbol 7, was bedeutet, dass der DC-Koeffizient in diesem Block mit 7 Bits codiert ist. Wir lesen also die nächsten 7 Bits ein:
11110 0000111 1011
Wir dürfen nun diese Zahl nicht einfach als 7 interpretieren, sondern müssen sie anhand der JPEG-Spezifikation in eine vorzeichenbehaftete Zahl umwandeln:
Also rechnen wir: 7 - 127 = -120. Da der DC-Koeffizient nicht direkt, sondern als Differenz zum vorherigen DC-Koeffizienten codiert ist, müssen wir diesen Wert noch zum vorherigen DC-Koeffizienten addieren. Da dies der erste Block ist, nehmen wir an, dass der vorherige DC-Koeffizient 0 war, und erhalten somit einen DC-Koeffizienten von -120 für diesen Block.
Unser DCT-Block sieht bisher wie folgt aus:
| -120 | |||||||
Direkt auf die DC-Differenz folgen die AC-Koeffizienten. Schauen wir uns wieder den Hexdump an:
00000260 fa ff da 00 0c 03 01 00 02 11 03 11 00 3f 00 f0 |.............?..| 00000270 7b 9d 26 64 7c c4 d9 52 7e e9 ed 59 b3 44 23 60 |{.&d|..R~..Y.D#`| 00000280 92 2e c6 3d 33 5d f5 c5 96 d2 44 67 38 ec 45 72 |...=3]....Dg8.Er|
Hier wird die AC-Tabelle im Slot 0 verwendet, die insgesamt 162 Codes definiert, von denen wir für dieses Beispiel nur einen Auszug benötigen. Verwende die Buttons, um zu sehen, wie der Bitstream decodiert wird (die Bits des bereits decodierten DC-Koeffizienten sind weiterhin markiert):
| Code | 00 | 01 | 100 | 1010 | 1011 | 1100 | 11010 | 11011 | 11100 | 111010 | 111011 | 1111000 | 1111001 | ... | 111110111 | ... |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | 0x01 | 0x02 | 0x03 | 0x00 | 0x04 | 0x11 | 0x05 | 0x12 | 0x21 | 0x31 | 0x41 | 0x06 | 0x13 | ... | 0x32 | ... |
1011.1011 gehört das Symbol 0x04. Dieses Byte beinhaltet zwei Informationen:
1001.Es gibt zwei spezielle Symbole bei der Decodierung der AC-Koeffizienten:
0x00: EOB (End of Block) → Alle restlichen Koeffizienten in diesem Block haben den Wert 0.0xF0: ZRL (Zero Run Length) → Es werden 16 Nullen in der DCT-Matrix eingetragen, bevor der nächste Koeffizient decodiert wird.Jeder Block wird anschließend dequantisiert, indem die Koeffizienten komponentenweise mit den entsprechenden Werten aus der Quantisierungstabelle multipliziert werden. In unserem Beispiel verwenden wir die folgende Quantisierungstabelle für die Y-Komponente, die wir vorher aus dem ersten DQT-Segment erstellt haben:
Nachdem alle Koeffizienten eines Blocks decodiert wurden, müssen wir die inverse DCT (iDCT) anwenden, um die Pixelwerte zu erhalten. Die iDCT wird auf die 8x8-DCT-Matrix angewendet und liefert eine 8x8-Matrix mit den Pixelwerten zurück.
Du kannst folgende Formel für die iDCT verwenden:

Da die resultierenden Werte nach der iDCT noch im Bereich von -128 bis 127 liegen, müssen wir sie um 128 verschieben, um den Bereich von 0 bis 255 zu erhalten.
Wenn wir 6 Blöcke decodiert haben (4×Y, 1×Cb, 1×Cr), können wir die MCU von 16x16 Pixeln rekonstruieren. Dazu müssen wir die Blöcke der Y-Komponente entsprechend ihrer Position in der MCU anordnen und die Blöcke der Cb- und Cr-Komponenten auf die Größe von 16x16 Pixeln hochskalieren (da sie nur 8x8 Pixel groß sind). Anschließend können wir die iDCT auf jeden Block anwenden, um die Pixelwerte zu erhalten.
Nachdem wir die Pixelwerte für die Y-, Cb- und Cr-Komponenten erhalten haben, müssen wir diese in den RGB-Farbraum konvertieren, um das Bild korrekt darstellen zu können. Die Konvertierung erfolgt mit den folgenden Formeln:

Anschließend müssen die RGB-Werte noch einmal auf den Bereich von 0 bis 255 beschränkt werden, da sie durch die Berechnung auch Werte außerhalb dieses Bereichs annehmen können.