powered by 
In diesem Kapitel entwickelst du eine Datenbank für eine Videothek, indem du ein Entity-Relationship-Diagramm erstellst und dieses in eine relationale Datenbank überführst. Anschließend lädst du Beispieldaten in die Datenbank und führst erste Abfragen durch. Das Datenmodell wird anschließend Schritt für Schritt erweitert.
Stelle zuerst sicher, dass du keinen Ordner geöffnet hast. Um sicherzugehen, drücke einfach den Shortcut für »Ordner schließen«: StrgK und dann F. Dein Workspace sollte jetzt ungefähr so aussehen:
Für diese Anleitung brauchst du ein Repository, das du klonen kannst, indem du auf den blauen Button »Clone Repository« klickst. Gib die folgende URL ein und bestätige mit Enter:
https://github.com/specht/videothek.git

Als nächstes musst du angeben, in welches Verzeichnis du das Repository klonen möchtest. Bestätige den Standardpfad /workspace/ mit Enter.
Beantworte die Frage »Would you like to open the cloned repository?« mit »Open«.
Du siehst nun auf der linken Seite ein paar Dateien, die wir für dieses Projekt verwenden werden:
import-data.rb wird verwendet, um die Daten in die Datenbank zu importierenvideothek.rb ist unser Hauptprogramm, das wir später verwenden werden, um den Katalog zu durchsuchen, Filme auszuleihen und zurückzugebenÖffne die Datei genres.txt und schau dir die Daten an:
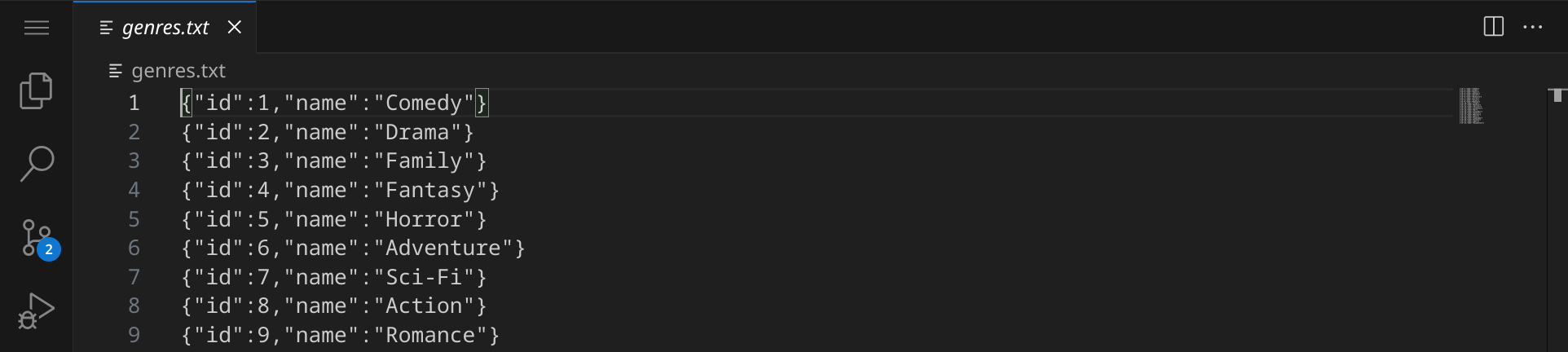
In jeder Zeile siehst du einen Datensatz, der ein Genre beschreibt und im JSON-Format vorliegt. Die Datei movies.txt enthält ähnliche Daten, die Filme beschreiben:
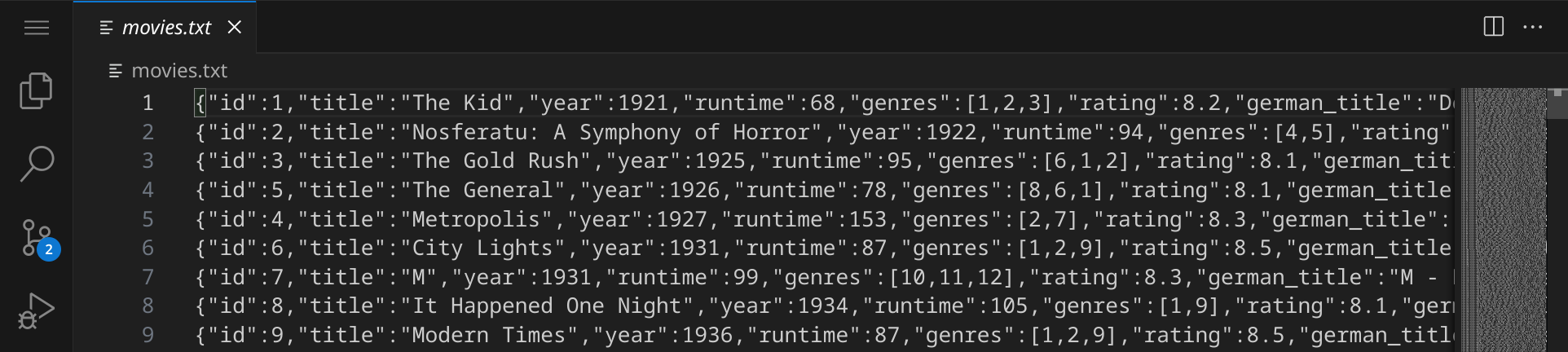
Nehmen wir uns einen Datensatz und schauen ihn formatiert an, so erkennen wir eine Struktur:
{ "id": 2, "title": "Nosferatu: A Symphony of Horror", "year": 1922, "runtime": 94, "genres": [ 4, 5 ], "rating": 7.8, "german_title": "Nosferatu, eine Symphonie des Grauens", "crew": { "actor": [ 8815, 5049, 9867, 8817, 8805, 6421, 2933, 5028, 7591, 5441 ], "director": [ 1549 ], "writer": [ 9305, 4751 ], "producer": [ 5063 ], "composer": [ 1454, 4378 ], "cinematographer": [ 2039 ] } }
Es gibt verschiedene Tools, um ein Entity-Relationship-Diagramm (ERD) zu erstellen. In diesem Tutorial verwenden wir die Erweiterung »ERD Editor« für Visual Studio Code. Um die Erweiterung zu installieren, klicke auf das Erweiterungs-Symbol  in der Seitenleiste oder drücke StrgShiftX. Suche nach der Erweiterung »ERD Editor« und installiere sie.
in der Seitenleiste oder drücke StrgShiftX. Suche nach der Erweiterung »ERD Editor« und installiere sie.

Erstelle eine neue Datei mit StrgAltN und speichere die Datei unter dem Dateinamen videothek.erd, indem du StrgS drückst, den Namen eingibst und mit Enter bestätigst.

Die Erweiterung »ERD Editor« erkennt, dass es sich bei der Datei um ein ERD handelt und öffnet den Editor, in dem wir das Diagramm erstellen können.
Erstelle das folgende Diagramm:
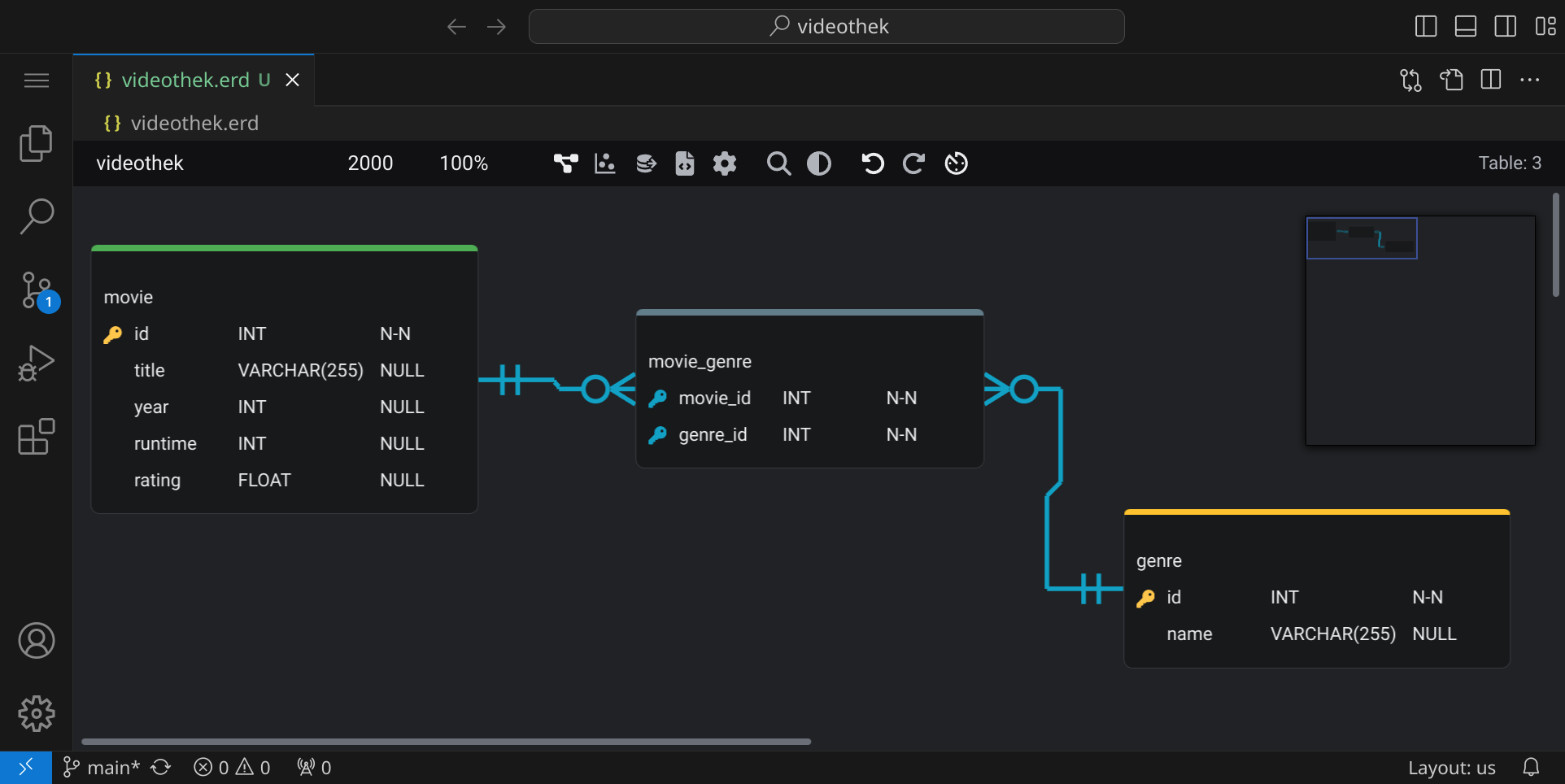
_).movie_genre entstehen automatisch, wenn du die Beziehung zwischen den Tabellen movie und genre herstellst (Fremdschlüssel sind pink markiert).id heißen, musst du sie in movie_id und genre_id umbenennen, damit es keine Verwechslungen gibt.movie_genre zusätzlich als Primärschlüssel, sie sollten dann blau dargestellt werden.N-N steht für »NOT NULL« und bedeutet, dass der Wert nicht leer sein darf.Wenn du fertig bist, kannst du das Diagramm speichern und den SQL-Code exportieren, den wir später verwenden werden, um die Datenbankstruktur zu erstellen. Klicke dazu mit rechts auf den Hintergrund und wähle »Export« / »Schema SQL«.
Wähle als Dateinamen videothek.sql und bestätige mit Enter:

Schau dir die Datei videothek.sql an, die den SQL-Code für die Datenbankstruktur enthält:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
CREATE TABLE genre ( id INT NOT NULL, name VARCHAR(255) NULL , PRIMARY KEY (id) ); CREATE TABLE movie ( id INT NOT NULL, title VARCHAR(255) NULL , year INT NULL , runtime INT NULL , rating FLOAT NULL , PRIMARY KEY (id) ); CREATE TABLE movie_genre ( movie_id INT NOT NULL, genre_id INT NOT NULL, PRIMARY KEY (movie_id, genre_id) ); ALTER TABLE movie_genre ADD CONSTRAINT FK_movie_TO_movie_genre FOREIGN KEY (movie_id) REFERENCES movie (id); ALTER TABLE movie_genre ADD CONSTRAINT FK_genre_TO_movie_genre FOREIGN KEY (genre_id) REFERENCES genre (id); |
Diese SQL-Statements sorgen dafür, dass die Tabellen movie, genre und movie_genre mit den entsprechenden Attributen und Primärschlüsseln erstellt werden. Zusätzlich werden die Fremdschlüsselbeziehungen zwischen den Tabellen definiert.
Um den Code auszuführen, geben wir die Befehle an mycli. Öffne dazu ein Terminal und gib folgenden Befehl ein:
mycli < videothek.sql

Du kannst nun mit mycli überprüfen, ob die Tabellen korrekt erstellt wurden:
mycli

Solange du in mycli bist, kannst du SQL-Befehle eingeben. Um die Tabellen anzuzeigen, gib folgenden Befehl ein:
SHOW TABLES;
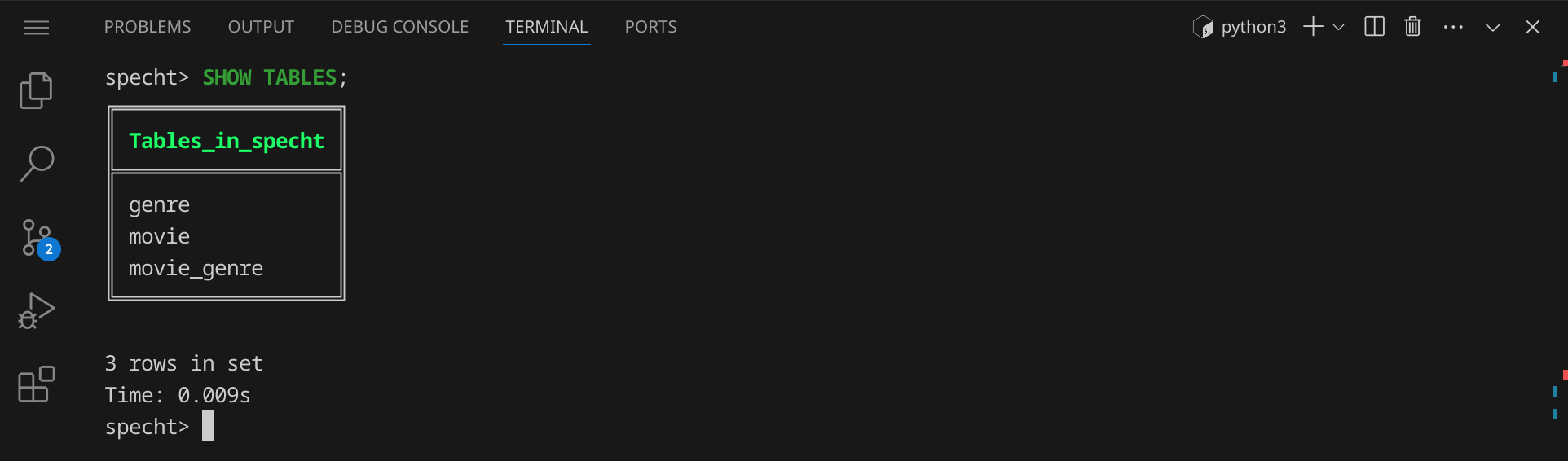
Du siehst, dass die Tabellen existieren, allerdings sind sie noch leer:

Um die Tabellen mit Daten zu füllen, verwenden wir das Ruby-Skript import-data.rb. Dieses Skript liest die Textdateien movies.txt und genres.txt und fügt die Daten in die Datenbank ein.
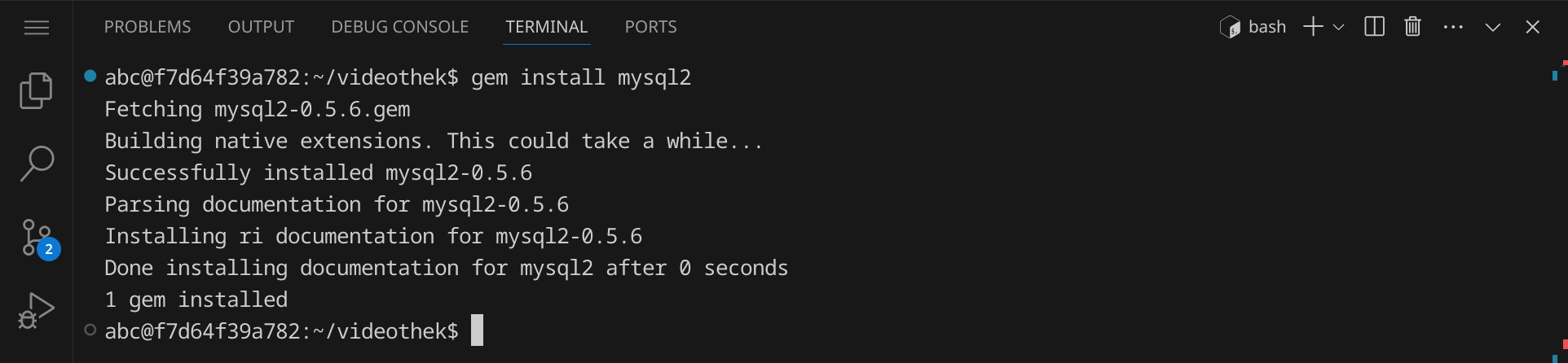
Bevor wir das Skript ausführen können, müssen wir noch das Rubygem mysql2 installieren. Öffne dazu ein Terminal und gib folgenden Befehl ein:
gem install mysql2
Wenn alles korrekt funktioniert, sollte deine Ausgabe in etwa so aussehen:
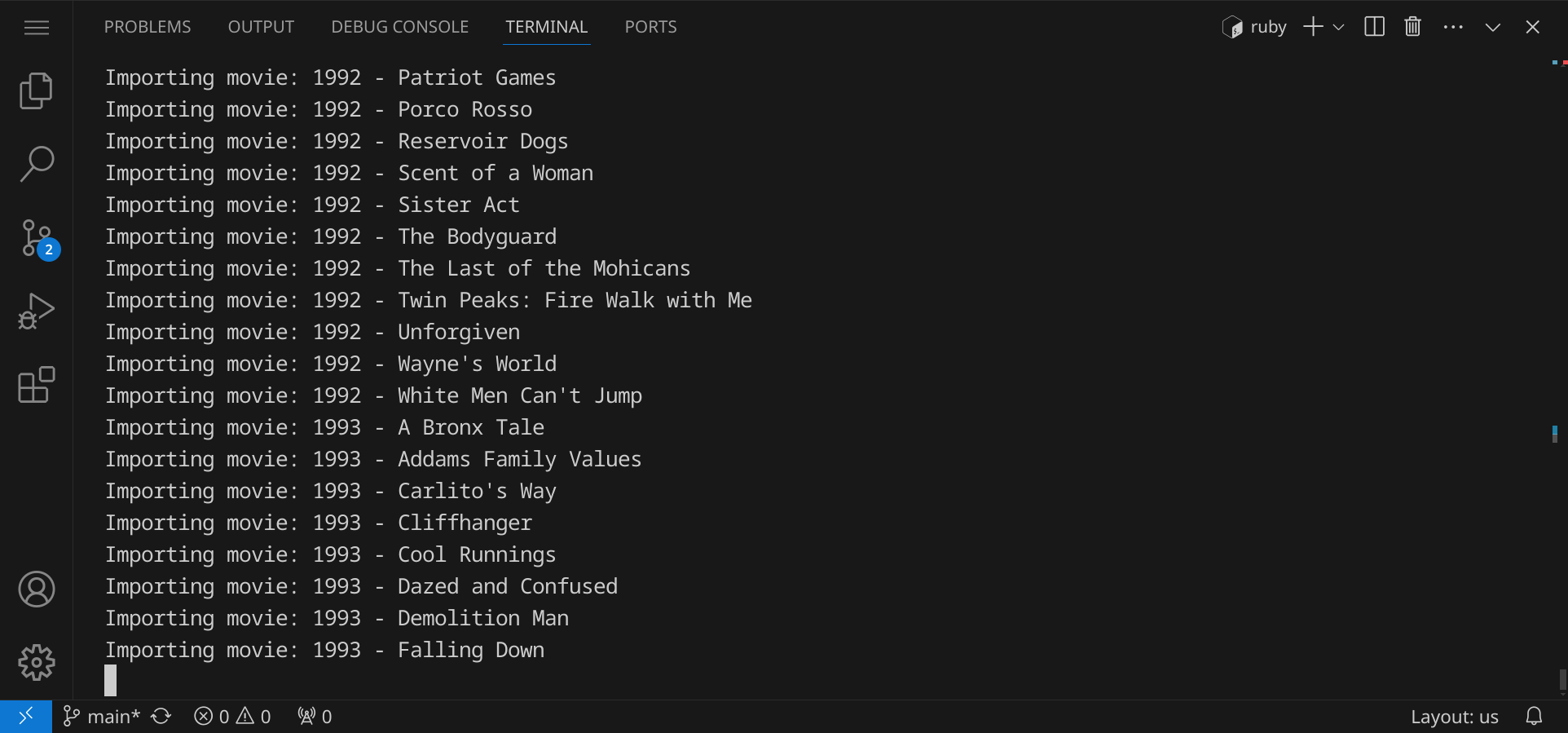
Führe anschließend das Skript import-data.rb im Terminal aus:
ruby import-data.rb
mycli. Beende das Programm mit dem Befehl exit (oder drücke einfach StrgD) und gib den Befehl im Terminal erneut ein.
Du solltest sehen, wie die Genres und Filme nach und nach importiert werden:
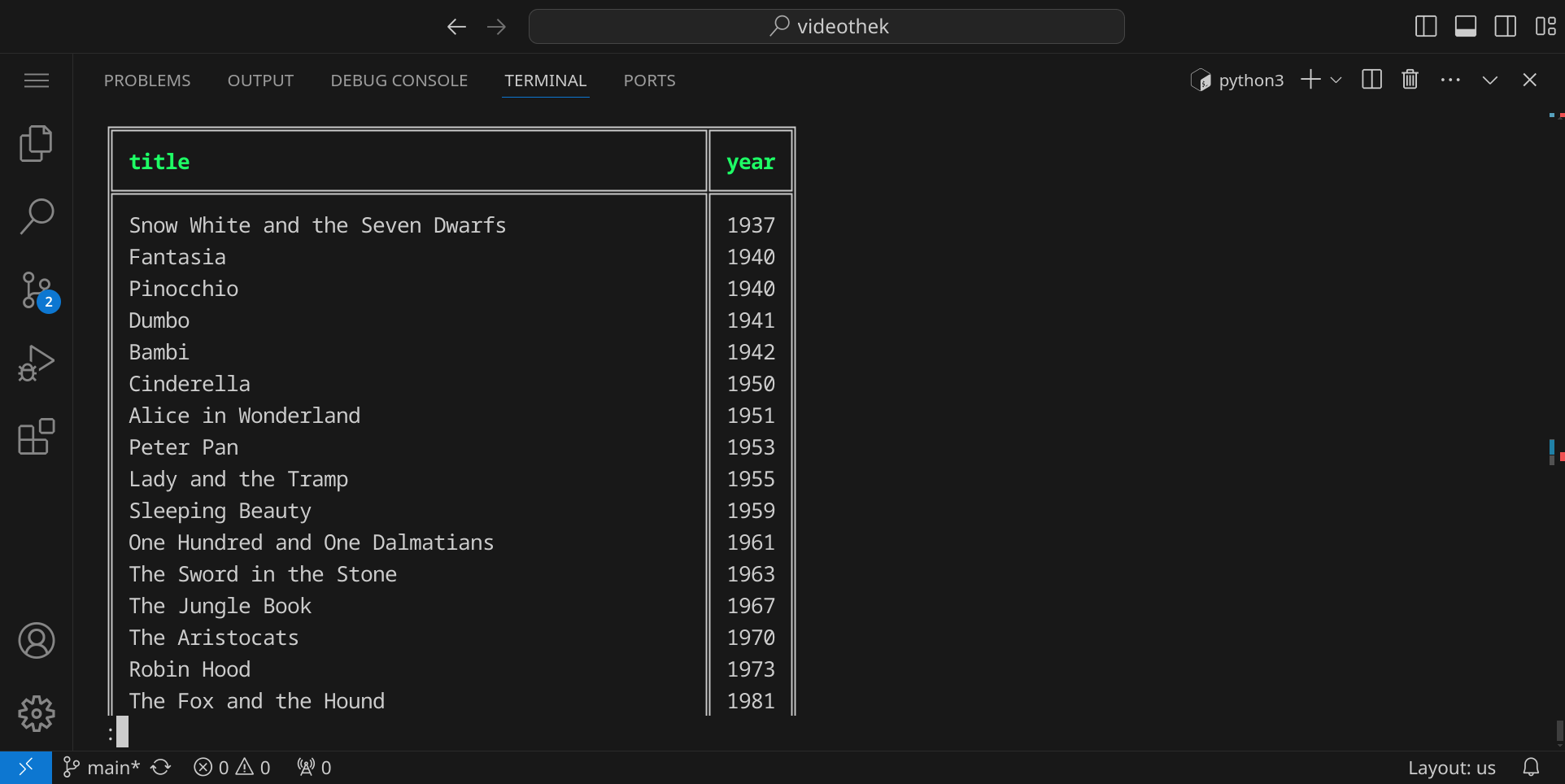
Du kannst nun in mycli überprüfen, ob die Daten korrekt importiert wurden:
SELECT title, year FROM movie JOIN movie_genre JOIN genre ON movie.id = movie_genre.movie_id AND movie_genre.genre_id = genre.id WHERE genre.name = "Animation";
Bevor wir das Hauptprogramm videothek.rb starten können, müssen wir noch das Rubygem tty installieren (es handelt sich dabei um eine Familie von Rubygems, die es ermöglichen, interaktive Konsolenanwendungen zu erstellen). Öffne dazu ein Terminal und gib folgenden Befehl ein:
gem install tty
Die Installation dauert ein paar Sekunden, und wenn sie erfolgreich abgeschlossen ist, siehst du eine Ausgabe wie diese:
Führe anschließend das Skript videothek.rb im Terminal aus:
ruby videothek.rb

Du kannst nun die Pfeiltasten ↑ und ↓, die Eingabetaste Enter und die Escape-Taste Esc verwenden, um durch die Menüs zu navigieren.
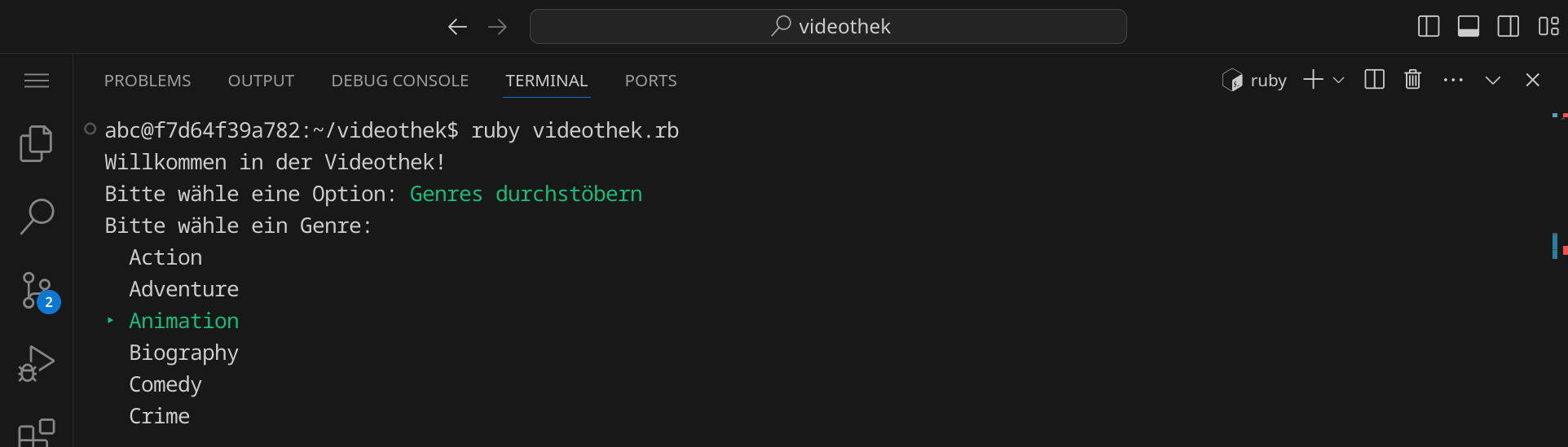
Wähle »Genres durchstöbern« und dann »Animation«, um eine Liste der Animationsfilme anzuzeigen:
An dieser Stelle wird das Programm mit einer Fehlermeldung beendet, da der entsprechende Teil noch nicht implementiert ist:
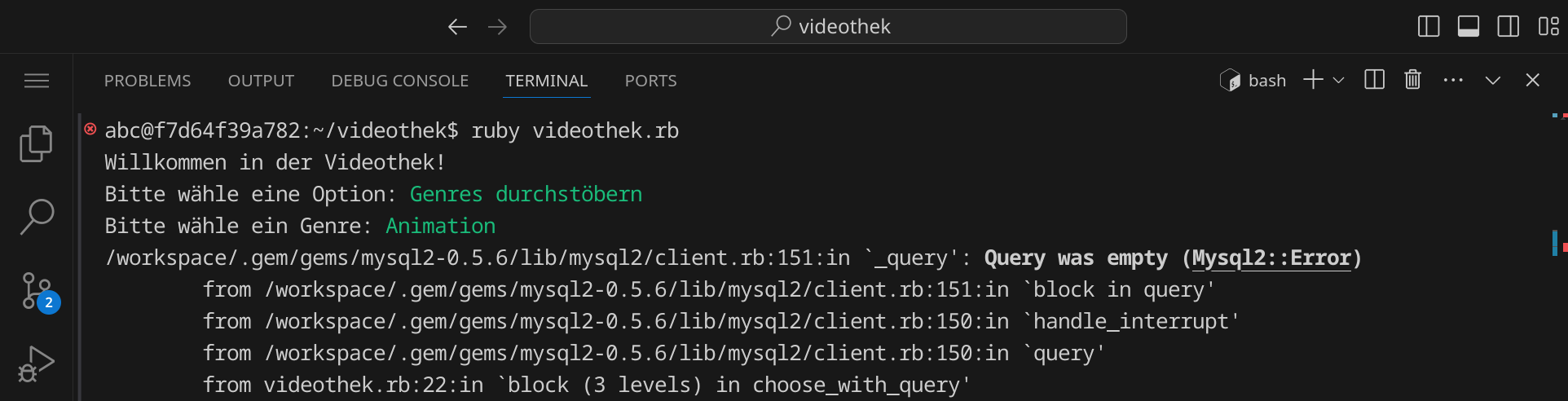
Scrolle ggfs. nach oben, bis du den Anfang der Fehlermeldung siehst. Die komplette Fehlermeldung siehst du hier:
/workspace/.gem/gems/mysql2-0.5.6/lib/mysql2/client.rb:151:in `_query': Query was empty (Mysql2::Error)
from /workspace/.gem/gems/mysql2-0.5.6/lib/mysql2/client.rb:151:in `block in query'
from /workspace/.gem/gems/mysql2-0.5.6/lib/mysql2/client.rb:150:in `handle_interrupt'
from /workspace/.gem/gems/mysql2-0.5.6/lib/mysql2/client.rb:150:in `query'
from videothek.rb:22:in `block (3 levels) in choose_with_query'
from /workspace/.gem/gems/tty-prompt-0.21.0/lib/tty/prompt/list.rb:221:in `call'
from /workspace/.gem/gems/tty-prompt-0.21.0/lib/tty/prompt.rb:242:in `invoke_select'
from /workspace/.gem/gems/tty-prompt-0.21.0/lib/tty/prompt.rb:279:in `select'
from videothek.rb:20:in `block (2 levels) in choose_with_query'
from videothek.rb:19:in `catch'
from videothek.rb:19:in `block in choose_with_query'
from videothek.rb:17:in `loop'
from videothek.rb:17:in `choose_with_query'
from videothek.rb:52:in `browse_movies_by_genre'
from videothek.rb:31:in `block in choose_with_query'
from videothek.rb:17:in `loop'
from videothek.rb:17:in `choose_with_query'
from videothek.rb:71:in `block in <main>'
from videothek.rb:59:in `loop'
from videothek.rb:59:in `<main>'
Die erste Zeile gibt dir einen Hinweis darauf, was überhaupt passiert ist. »Query was empty« bedeutet, dass eine leere Anfrage an die Datenbank gesendet wurde. In der Datei videothek.rb findest du die fehlerhafte Stelle in Zeile 51:
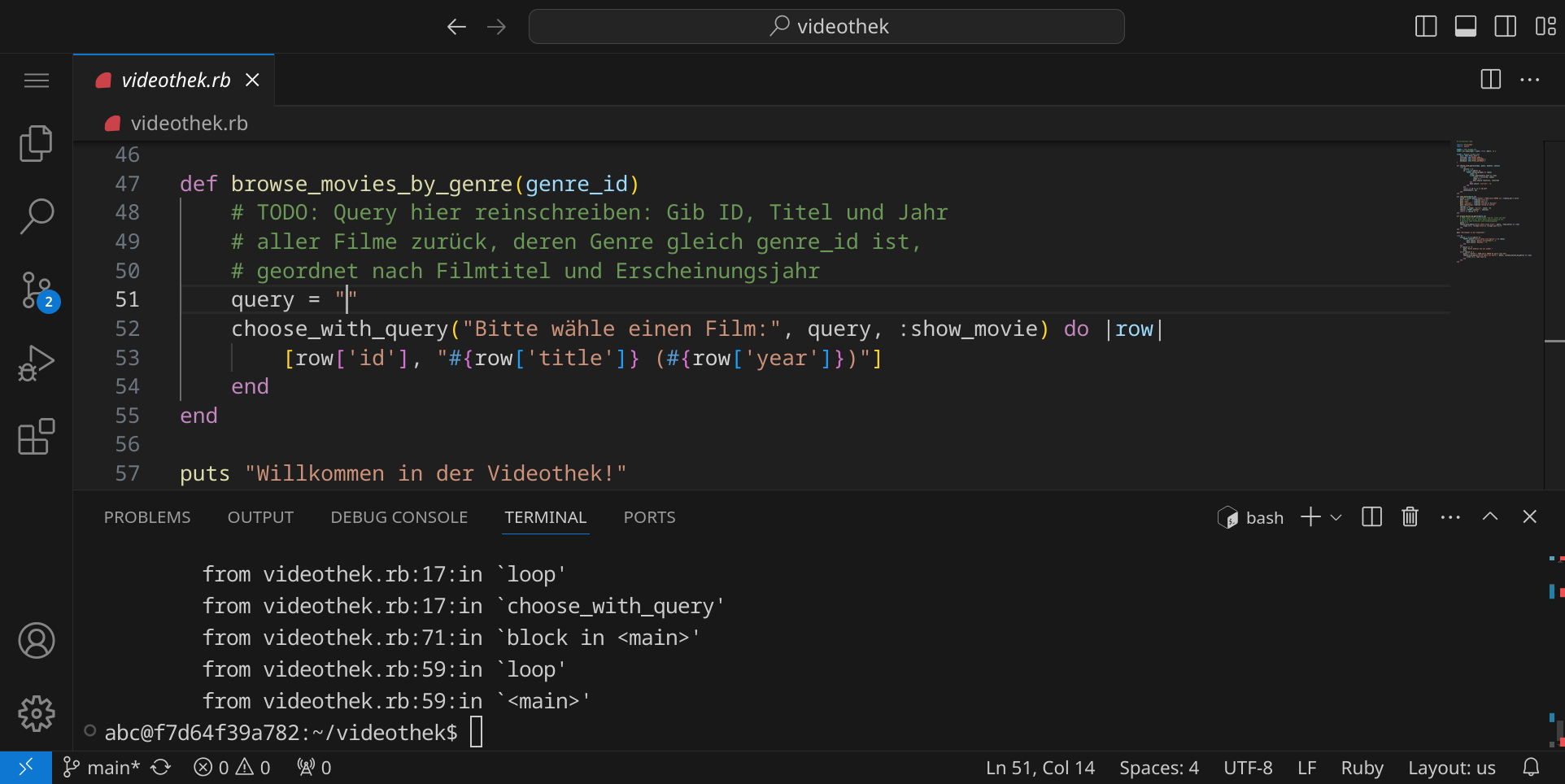
Wir werden nun die entsprechende Abfrage formulieren und in den Quelltext einfügen. Wir bekommen eine genre_id als Parameter übergeben und sollen nun alle Filme aus der Datenbank herausfiltern, die zu diesem Genre gehören.
Um die Abfrage zu entwickeln, können wir wieder mycli verwenden. Wir wollen alle Filme ausgeben, die zu einem bestimmten Genre gehören, dessen ID wir kennen. Dazu müssen wir die Tabellen movie und movie_genre mit Hilfe einer JOIN-Klausel verknüpfen.
Zu jedem JOIN gehört ein ON-Statement, das definiert, welche Einträge aus jeder der beteiligten Tabellen zusammengeführt werden sollen. In unserem Fall verknüpfen wir die Tabellen movie und movie_genre über die Spalte id und movie_id:
SELECT * FROM movie JOIN movie_genre ON movie.id = movie_genre.movie_id;
ON-Klausel ist ein wichtiger Bestandteil von JOIN-Anweisungen. Wenn du sie vergisst, wird die Datenbank alle möglichen Kombinationen der Einträge aller beteiligten Tabellen zurückgeben, was zu einem sehr großen Ergebnis – in unserem Fall 16,7 Millionen Einträgen – führen kann. Du wirst merken, dass die Abfrage sehr lange dauert, du kannst die Ausführung mit StrgC abbrechen.
Wir bekommen nun eine relativ große Tabelle, in der alle Filme mit ihren Genres aufgelistet sind. Ingesamt sind es über 6700 Einträge, obwohl es in unserer Datenbank nur ca. 2500 Filme gibt. Das liegt daran, dass jeder Film mehrere Genres haben kann und deshalb mehrfach durch die gestellte Abfrage zurückgegeben wird.
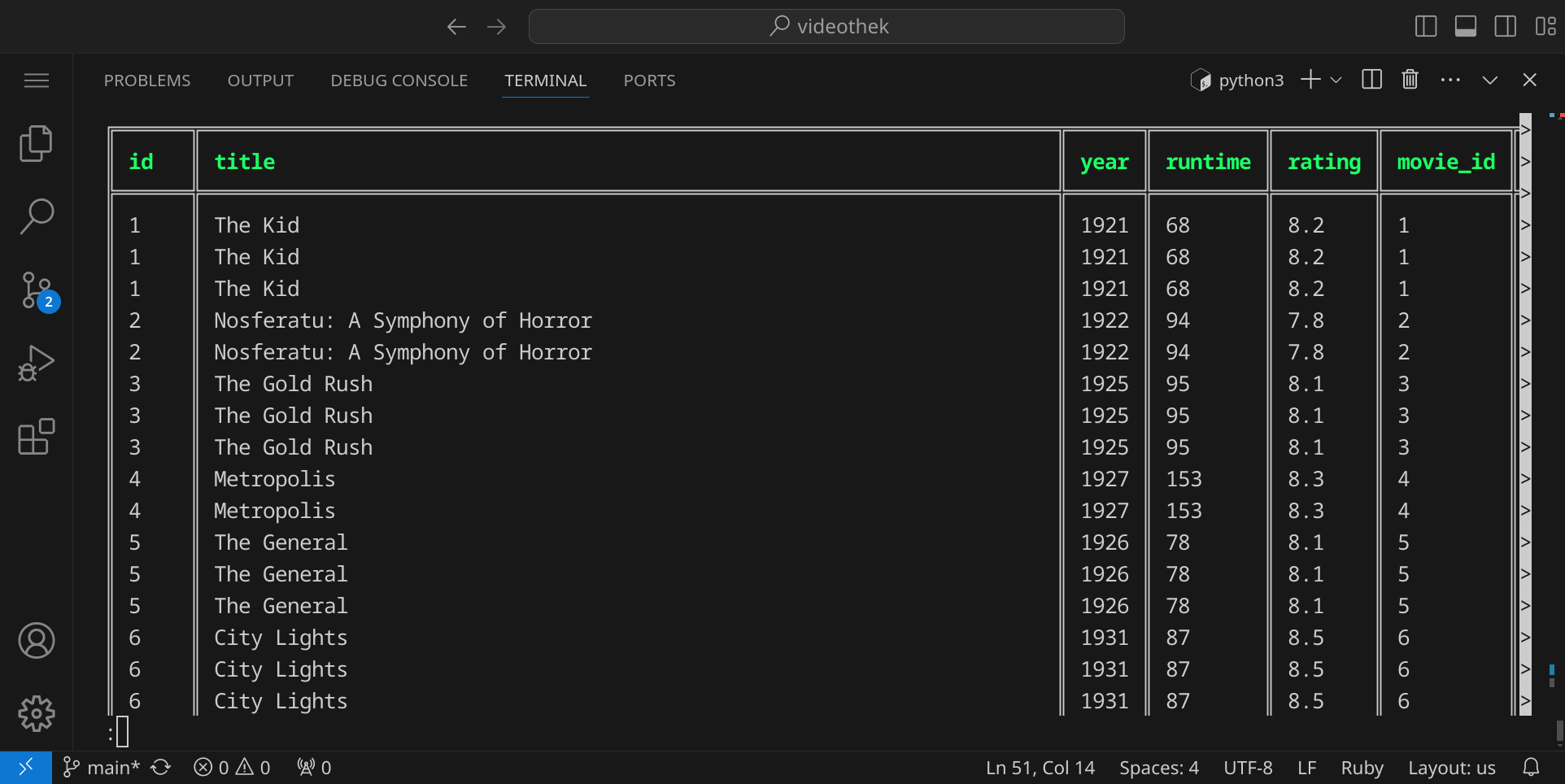
Da wir uns nur für die Spalten id, titel und year interessieren, können wir die Abfrage entsprechend anpassen. Zusätzlich zur ID des Films interessiert uns auch die ID des Genres, um später die Filme nach Genres filtern zu können:
SELECT id, genre_id, title, year FROM movie JOIN movie_genre ON movie.id = movie_genre.movie_id;
Wir erhalten nun eine Tabelle mit weniger Spalten (jedoch genauso vielen Zeilen):
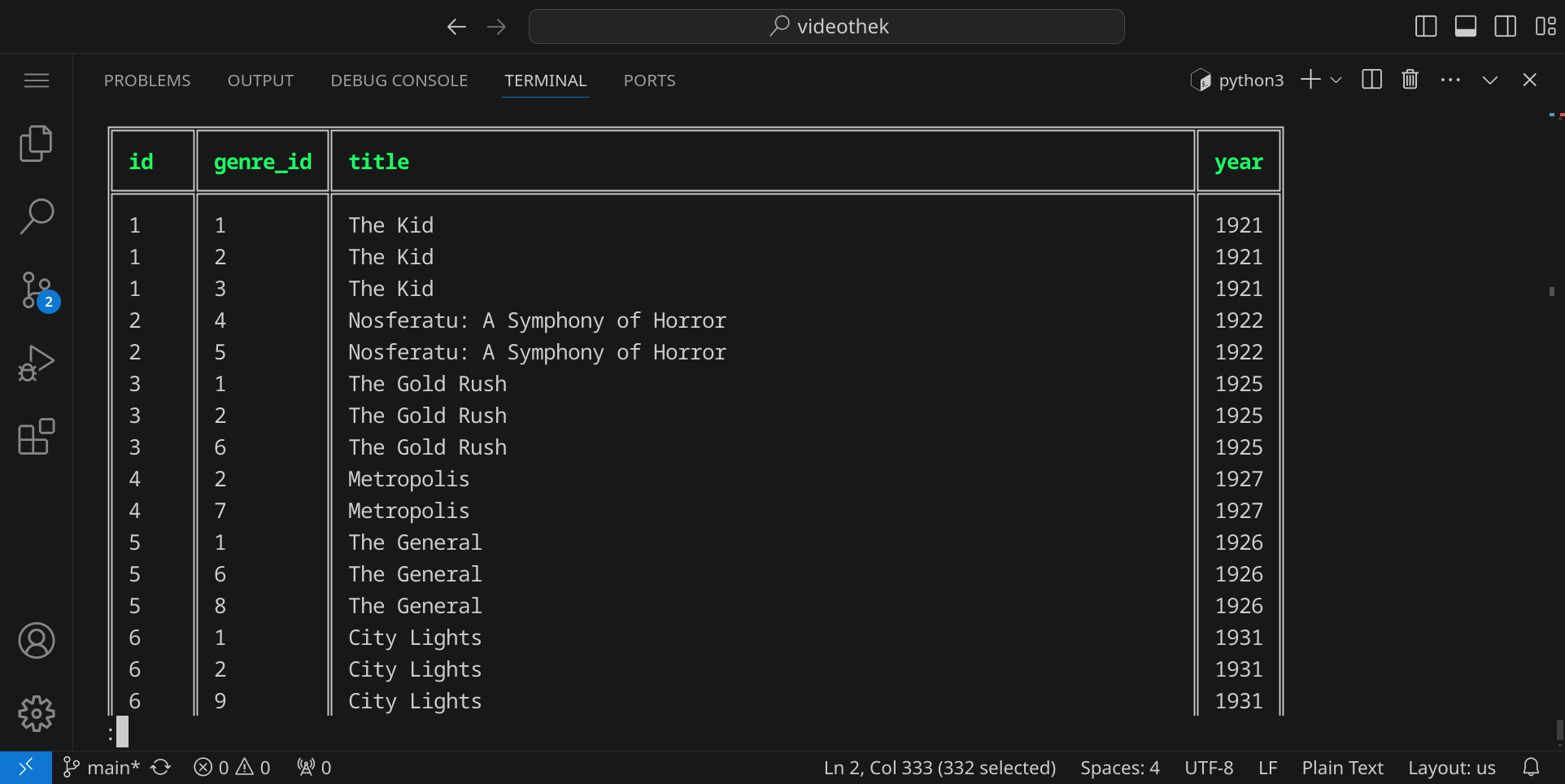
Um die Abfrage weiter einzuschränken, werden wir die WHERE-Klausel verwenden, um nur die Filme auszugeben, die zum Genre »Animation« gehören (dieses Genre hat in unserer Datenbank die ID 13):
SELECT id, genre_id, title, year FROM movie JOIN movie_genre ON movie.id = movie_genre.movie_id WHERE genre_id = 13;
Wir erhalten nun eine Auflistung von Animationsfilmen:
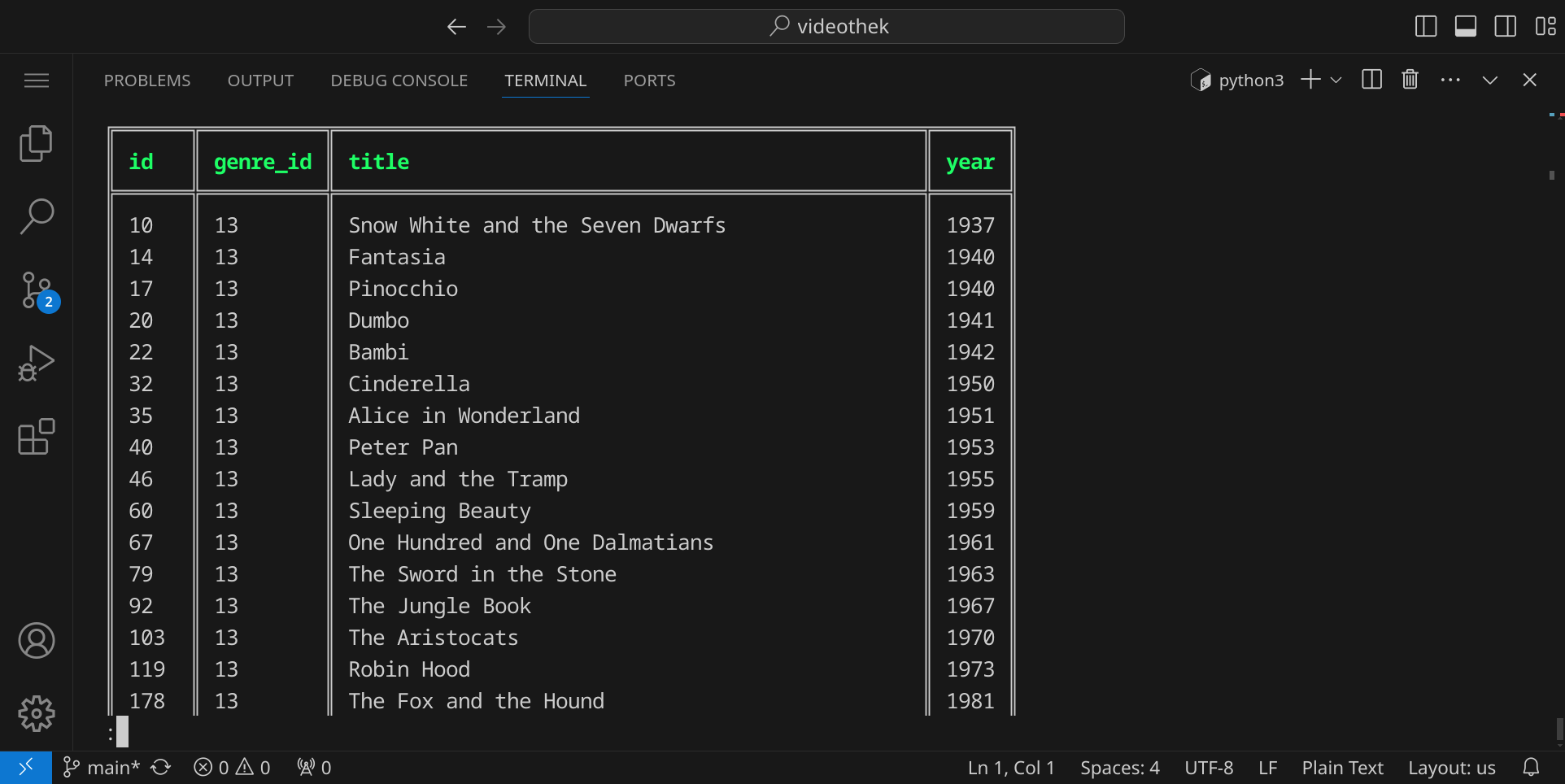
Da die Filme nach Titel und Jahr sortiert zurückgegeben werden sollen, fügen wir eine ORDER BY-Klausel hinzu:
SELECT id, title, year FROM movie JOIN movie_genre ON movie.id = movie_genre.movie_id WHERE genre_id = 13 ORDER BY title, year;
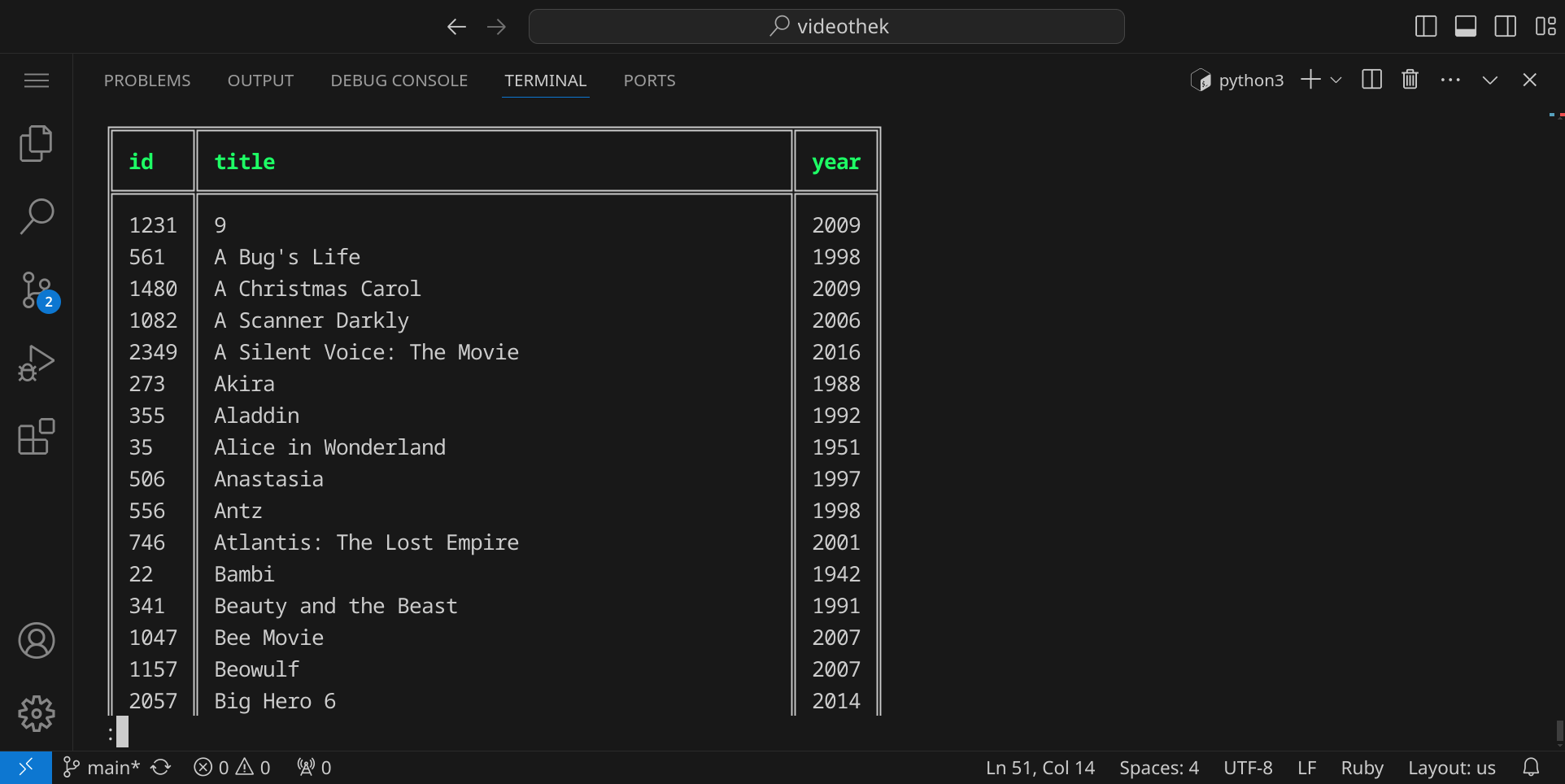
Unsere Abfrage ist nun also fertig und wir können sie in unser Ruby-Programm einfügen. Öffne dazu die Datei videothek.rb und ändere den Code in Zeile 51 wie folgt:
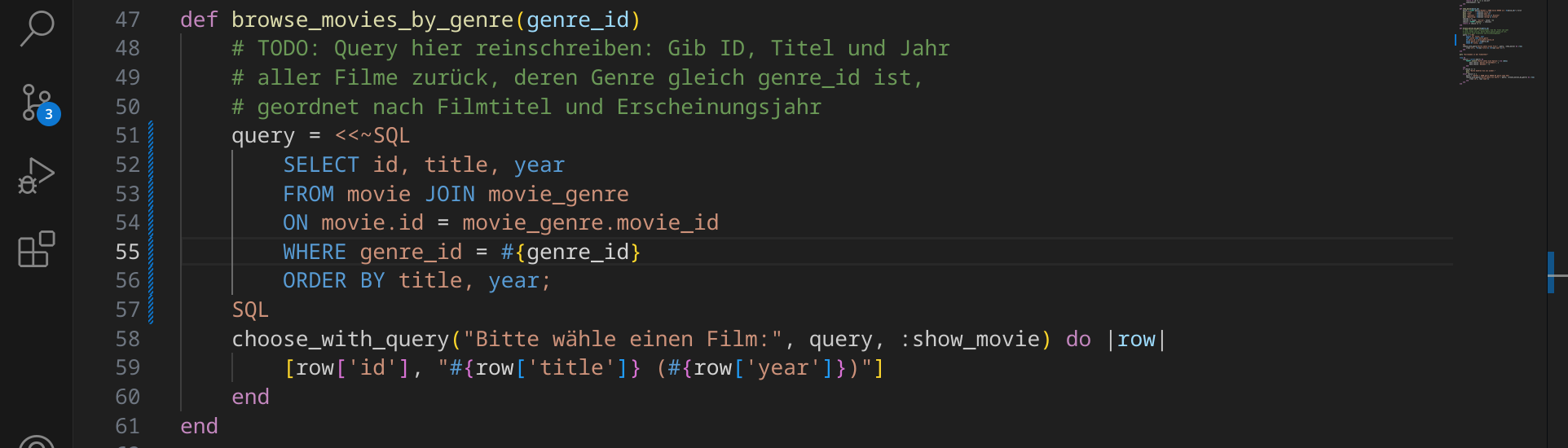
genre_id in Z. 47 übergeben und in Z. 55 mit Hilfe von String Interpolation (zwischen #{ und }) in die Abfrage eingefügt.<<~SQL markiert und mit SQL beendet (anstelle von SQL könnten wir auch jeden anderen Bezeichner wählen).Führe das Programm erneut aus:
ruby videothek.rb
Unsere Codeänderung hat funktioniert und wir können nun die Animationsfilme durchstöbern:
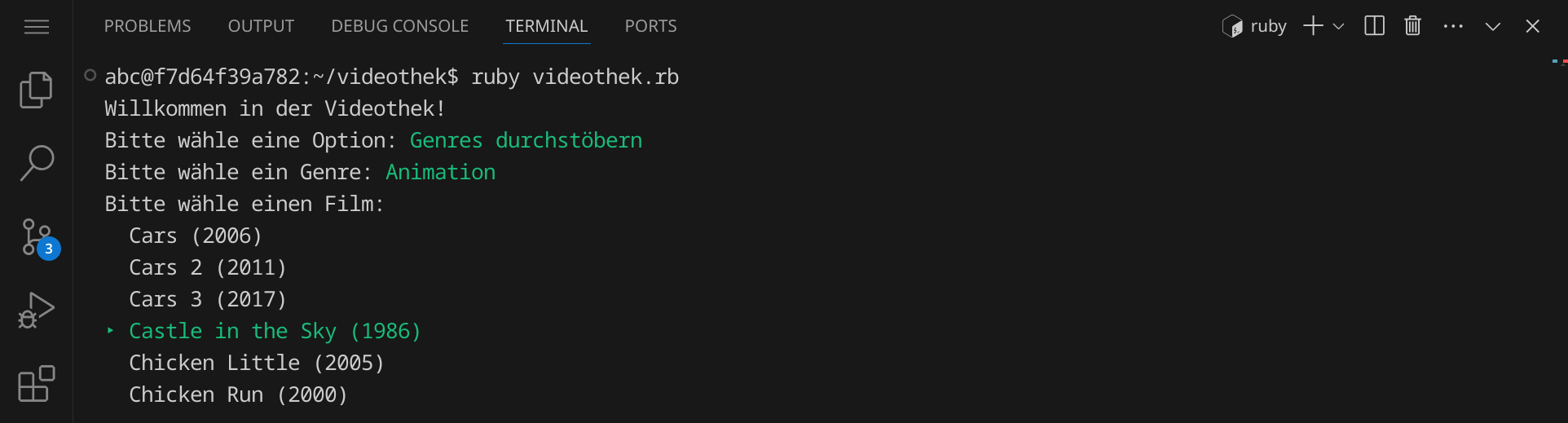
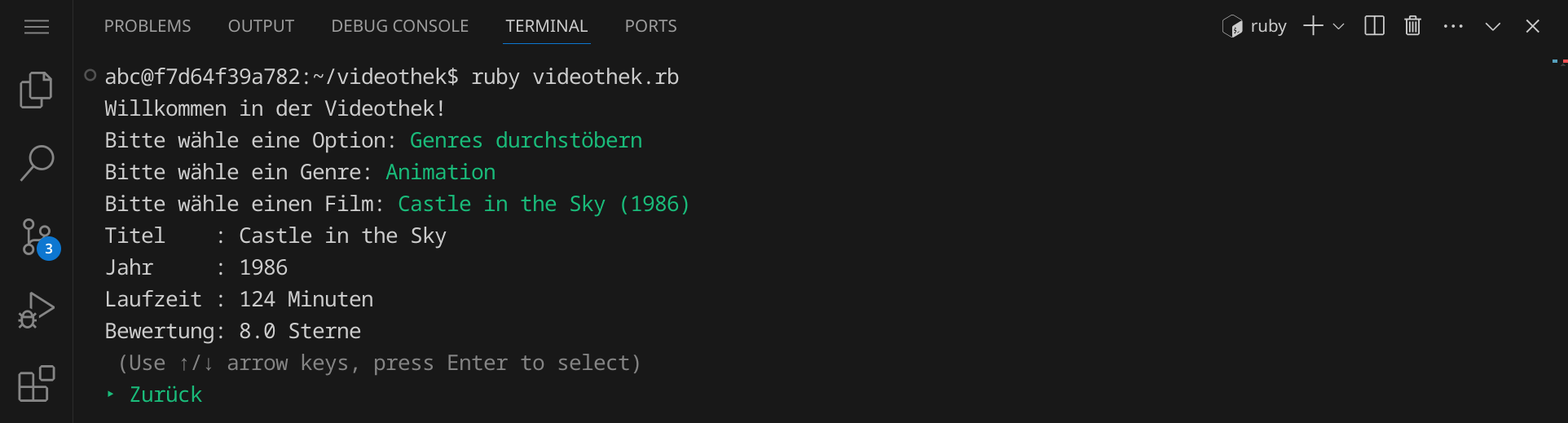
Wählen wir einen Film, so bekommen wir weitere Informationen angezeigt:
Versuche, die Videothek zu erweitern, indem du weitere Funktionen hinzufügst:
Wenn du diese Funktionen implementiert hast, kannst du dein Datenmodell um an den Filmen beteiligte Personen erweitern. Dazu musst du die Tabellen crew, movie_crew und job hinzufügen und die Beziehungen zwischen den Tabellen definieren:
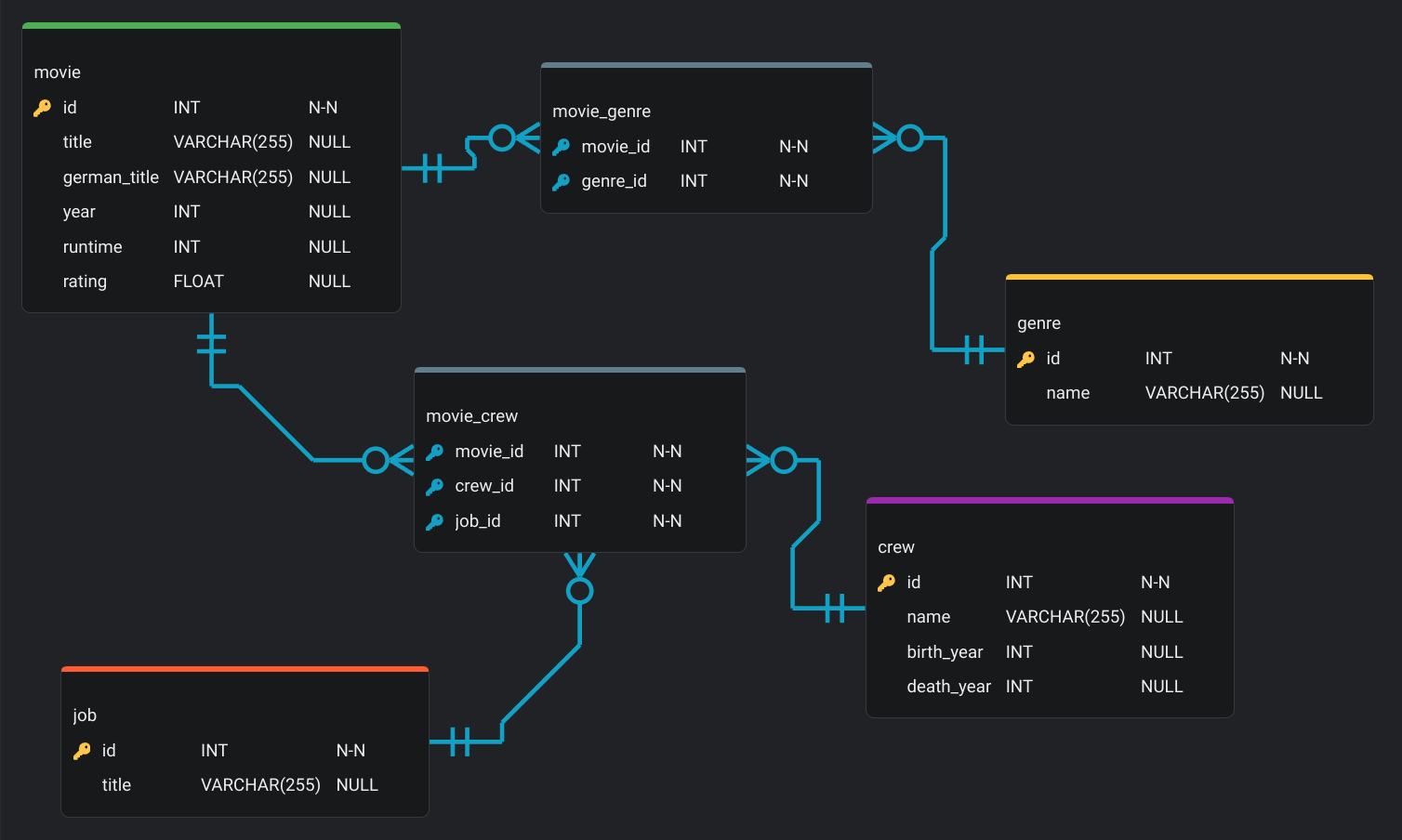
movie_crew werden diesmal drei Tabellen miteinander verbunden. Alle drei Fremdschlüssel sind gleichzeitig Primärschlüssel, da sie zusammen eindeutig sind, weil eine Person in einem Film mehrere Jobs haben kann.
Erweitere außerdem bei der Gelegenheit gleich die Tabelle movie um die Spalte german_title. Exportiere das SQL-Schema erneut als videothek.sql, setze deine Datenbank zurück und gib die Datei an mycli:
mycli < videothek.sql
Ersetze anschließend den Code in import-data.rb durch folgenden Code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
#!/usr/bin/env ruby require 'json' require 'mysql2' client = Mysql2::Client.new( host: ENV['MYSQL_HOST'], username: ENV['MYSQL_USER'], password: ENV['MYSQL_PASSWORD'], database: ENV['MYSQL_DATABASE'] ) job_id = {} File.open('movies.txt') do |f| f.each_line do |line| data = JSON.parse(line) data['crew'].keys.each do |job| job_id[job] ||= job_id.size + 1 end end end query = client.prepare("INSERT IGNORE INTO job (id, title) VALUES (?, ?)") job_id.each_pair do |job, id| puts "Importing job: #{job}" query.execute(id, job) end File.open('genres.txt') do |f| query = client.prepare("INSERT IGNORE INTO genre (id, name) VALUES (?, ?)") f.each_line do |line| data = JSON.parse(line) puts "Importing genre: #{data['name']}" query.execute(data['id'], data['name']) end end File.open('crew.txt') do |f| query = client.prepare("INSERT IGNORE INTO crew (id, name, birth_year, death_year) VALUES (?, ?, ?, ?)") f.each_line do |line| data = JSON.parse(line) puts "Importing crew: #{data['birth_year']} - #{data['name']}" query.execute(data['id'], data['name'], data['birth_year'], data['death_year']) end end File.open('movies.txt') do |f| query = client.prepare("INSERT IGNORE INTO movie (id, title, german_title, year, runtime, rating) VALUES (?, ?, ?, ?, ?, ?)") query2 = client.prepare("INSERT IGNORE INTO movie_genre (movie_id, genre_id) VALUES (?, ?)") query3 = client.prepare("INSERT IGNORE INTO movie_crew (movie_id, crew_id, job_id) VALUES (?, ?, ?)") f.each_line do |line| data = JSON.parse(line) puts "Importing movie: #{data['year']} - #{data['title']}" query.execute(data['id'], data['title'], data['german_title'], data['year'], data['runtime'], data['rating']) data['genres'].each do |genre| query2.execute(data['id'], genre) end data['crew'].each_pair do |job, crew_ids| crew_ids.each do |crew_id| query3.execute(data['id'], crew_id, job_id[job]) end end end end |
Führe das Skript aus – es wird diesmal etwas länger dauern, da mehr Daten importiert werden.
Versuche nun, die folgenden Funktionen zu implementieren:
Bis hierhin ist die Videothek "nur" eine Filmdatenbank. Um sie zu einer Videothek zu machen, fehlen noch die Nutzer und die Möglichkeit, Filme auszuleihen. Erweitere das Datenmodell um die entsprechenden Tabellen und füge die fehlende Funktionalität hinzu.
In diesem Kapitel hast du eine Datenbank für eine Videothek entwickelt, indem du ein Entity-Relationship-Diagramm erstellt und dieses in eine relationale Datenbank überführt hast. Anschließend hast du Beispieldaten in die Datenbank geladen und erste Abfragen durchgeführt. Das Datenmodell wurde Schritt für Schritt erweitert, um die Videothek um weitere Funktionen zu erweitern.