powered by 
In diesem Kapitel lernst du, wie du mit Dateien und Verzeichnissen im Terminal arbeiten kannst. Wir werden einige der wichtigsten Befehle kennenlernen, die wir verwenden können, um Dateien und Verzeichnisse zu erstellen, zu löschen, zu kopieren, zu verschieben und zu bearbeiten. Wir werden auch lernen, wie wir den Inhalt von Dateien anzeigen und analysieren können.
Stelle zuerst sicher, dass du keinen Ordner geöffnet hast. Um sicherzugehen, drücke einfach den Shortcut für »Ordner schließen«: StrgK und dann F. Dein Workspace sollte jetzt ungefähr so aussehen:
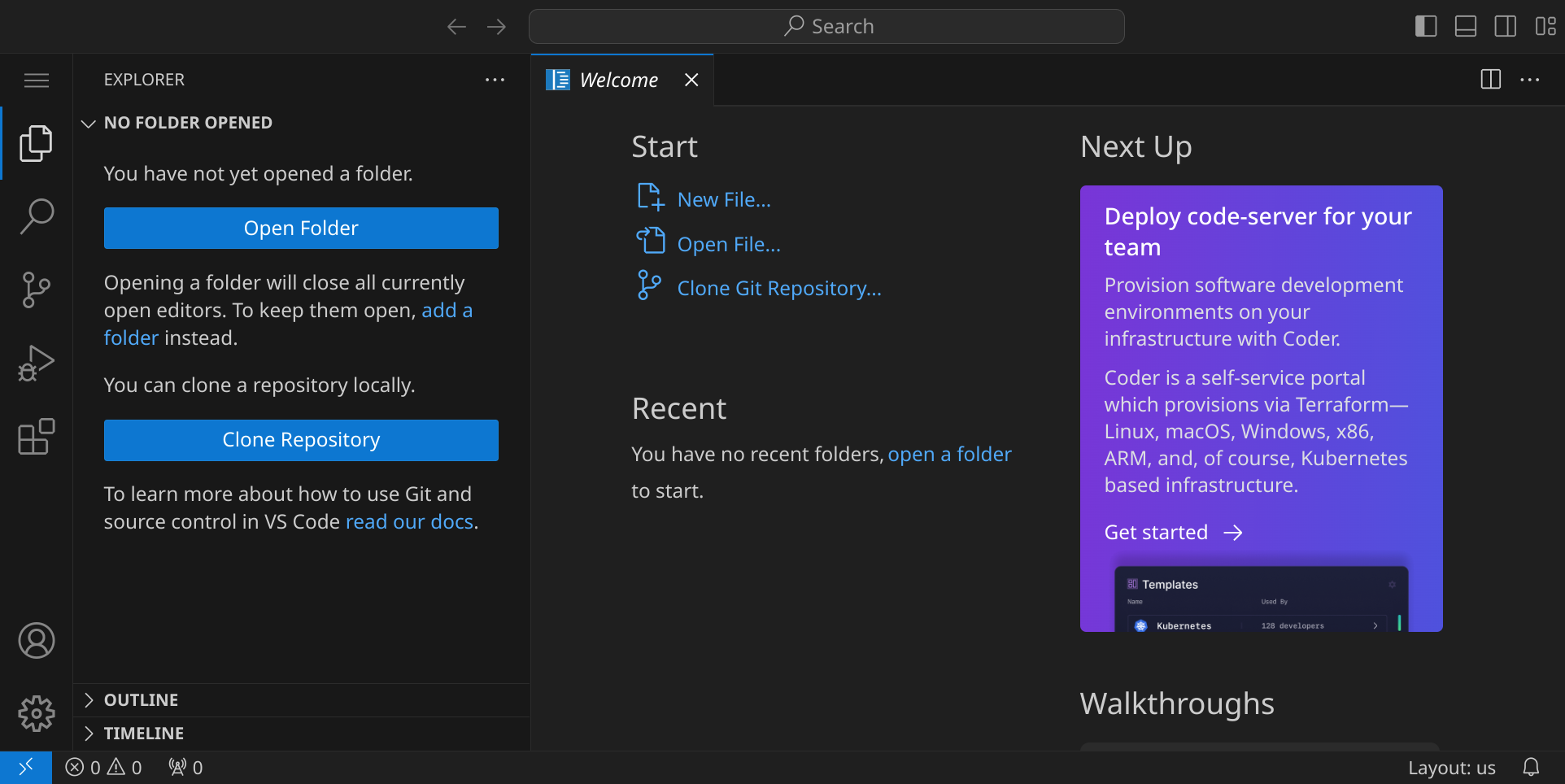
Schließe die linken Seitenleiste, indem du StrgB drückst, um mehr Platz zu haben. Öffne als nächstes das Terminal, indem du den Shortcut StrgJ drückst. Dein Workspace sollte jetzt ungefähr so aussehen:

Du kannst das Terminal auch maximieren, indem du auf den Pfeil in der rechten oberen Ecke des Terminals klickst. Die linke Seitenleiste kannst du jederzeit mit StrgB ein- und ausblenden.
Alle Befehle im Terminal einzugeben anstatt durch Mausklick, wird auch »Arbeiten auf der Kommandozeile« genannt. Im Terminal siehst du nun die Eingabeaufforderung, auch Prompt genannt, der dir u.a. anzeigt, in welchem Verzeichnis du dich befindest. Der Prompt sieht in etwa so aus:
abc@7a93efd91905:~$
Lass dich von dem Prompt nicht verwirren. Der Teil abc vor dem @ ist dein Benutzername, der Teil 7a93efd91905 nach dem @ ist der Name deines Computers, und der Teil nach dem : ist das aktuelle Verzeichnis. In diesem Fall ist das aktuelle Verzeichnis ~, welches die Abkürzung für dein Home-Verzeichnis ist. Das $ am Ende des Prompts zeigt an, dass du als normaler Benutzer angemeldet bist. Wenn du als Administrator angemeldet wärst, würde das $ durch ein # ersetzt.
Gib folgenden Befehl ein und drücke die Eingabetaste:
echo "Hello, World!"
Wenn du die Ausgabe Hello, World! siehst, hast du alles richtig gemacht. Herzlichen Glückwunsch!

Jetzt können wir anfangen, mit Dateien und Verzeichnissen zu arbeiten.
Gib folgenden Befehl ein, um eine Datei aus dem Internet herunterzuladen, die ein paar Beispieldateien enthält:
wget https://github.com/specht/workspace-files/raw/main/working-with-files.tar.gz
Die Ausgabe sollte in etwa so aussehen:
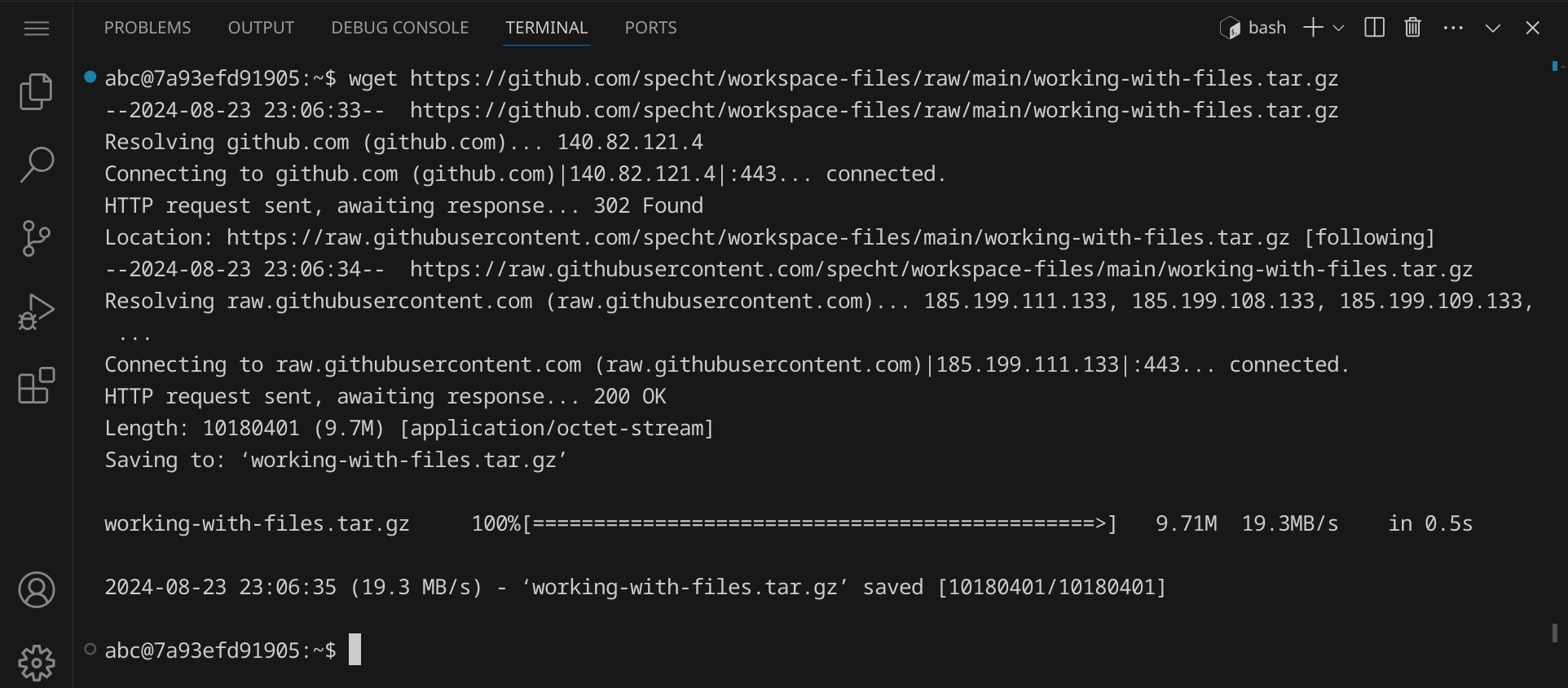
wget dieser Umleitung folgt. Die eigentliche Datei wird
dann heruntergeladen (»200 OK«) und die Ausgabe von wget zeigt dir den Fortschritt an.
Das Programm wget können wir dazu verwenden, um Dateien aus dem Internet herunterzuladen.
Die Datei wird standardmäßig im aktuellen Verzeichnis gespeichert. Schau nach, ob die Datei
angekommen ist, indem du den Befehl ls (kurz für »list«) eingibst:

Viele Befehle auf der Kommandozeile haben Optionen, die stets hinter dem Befehlsnamen mit einem - beginnen.
Probiere hier den Befehl ls -l (für »long«), um dir mehr Details anzeigen zu lassen:

Du siehst nun u.a., wie groß die Datei ist. Nutze den Befehl ls -lh (für »long human-readable«),
um die Größe in einer besser lesbaren Form zu sehen:

Die Datei ist also fast 10 MB groß.
Die Endung .tar.gz in unserem Beispiel zeigt an, dass es sich um ein komprimiertes Archiv handelt.
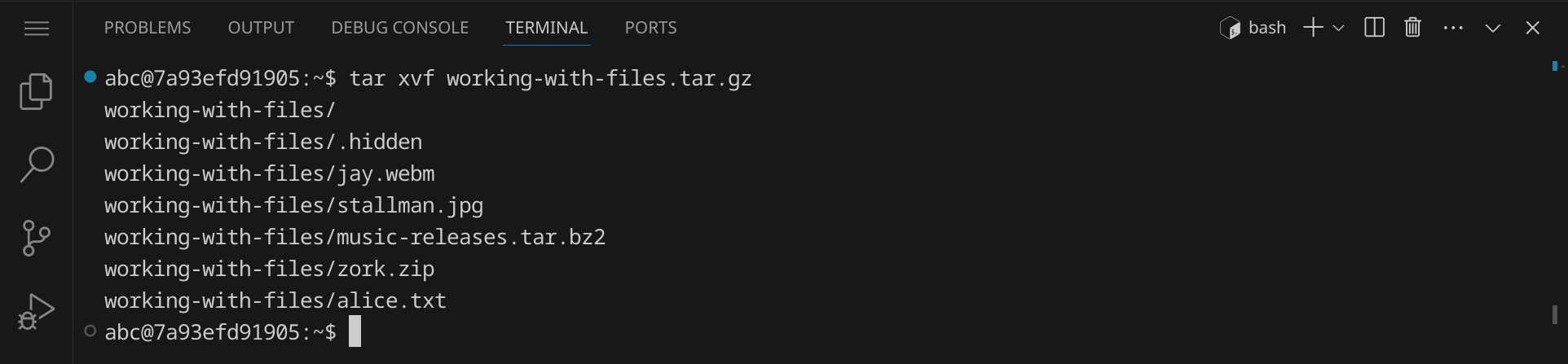
Wir können es mit dem Befehl tar entpacken:
tar xvf working-with-files.tar.gz
Die Optionen xvf stehen für extract, verbose und file. Das bedeutet, dass wir das
Archiv entpacken (x für »extract«), den Fortschritt anzeigen (v für »verbose«) und als
nächste Option den Dateinamen angeben (f für »file«).
Wenn du den Befehl ausführst, solltest du eine Meldung sehen, die dir anzeigt, welche Dateien entpackt wurden:
Gib noch einmal ls -l ein, um zu sehen, was sich nun in deinem Verzeichnis befindet:

Du solltest jetzt zusätzlich zur heruntergelandenen Archivdatei ein Verzeichnis namens
working-with-files sehen. Du erkennst an dem d am Anfang der Zeile, dass es sich um ein
Verzeichnis handelt.
clear verwenden oder einfach die Tastenkombination StrgL drücken.
pwd, cd, ls und file kennen.
Gib den Befehl pwd ein und drücke die Eingabetaste:

Der Befehl pwd steht für »print working directory« und zeigt dir das aktuelle Verzeichnis an, in dem du dich gerade befindest. Das aktuelle Verzeichnis wird auch im Prompt angezeigt – da im Workspace das Verzeichnis /workspace dein Home-Verzeichnis ist, wird es im Prompt mit ~ abgekürzt.
Wechsle nun in das entpackte Verzeichnis, indem du cd working-with-files eingibst und die Eingabetaste drückst. Du solltest nun im Verzeichnis working-with-files sein, was du leicht am Prompt erkennen kannst.

Wechsle wieder in das übergeordnete Verzeichnis, indem du cd .. eingibst und die Eingabetaste drückst. Du solltest nun wieder im Home-Verzeichnis sein.

Ein nützliches Feature des Terminals ist die Tab-Ergänzung. Wenn du anfängst, einen Befehl oder einen Dateinamen einzugeben, kannst du die Tab-Taste drücken, um den Befehl oder den Dateinamen automatisch zu vervollständigen. Wenn es mehrere Möglichkeiten gibt, kannst du die Tab-Taste zweimal drücken, um eine Liste der verfügbaren Optionen zu sehen.
Wechsle wieder in das Verzeichnis, aber gib diesmal nur cd w ein und drücke die Tab-Taste. Das Terminal vervollständigt den Befehl automatisch, weil es nur eine mögliche Option für einen Verzeichniswechsel gibt, die mit w beginnt.
Lass dir anschließend die Inhalte des Verzeichnisses mit ls -l anzeigen:
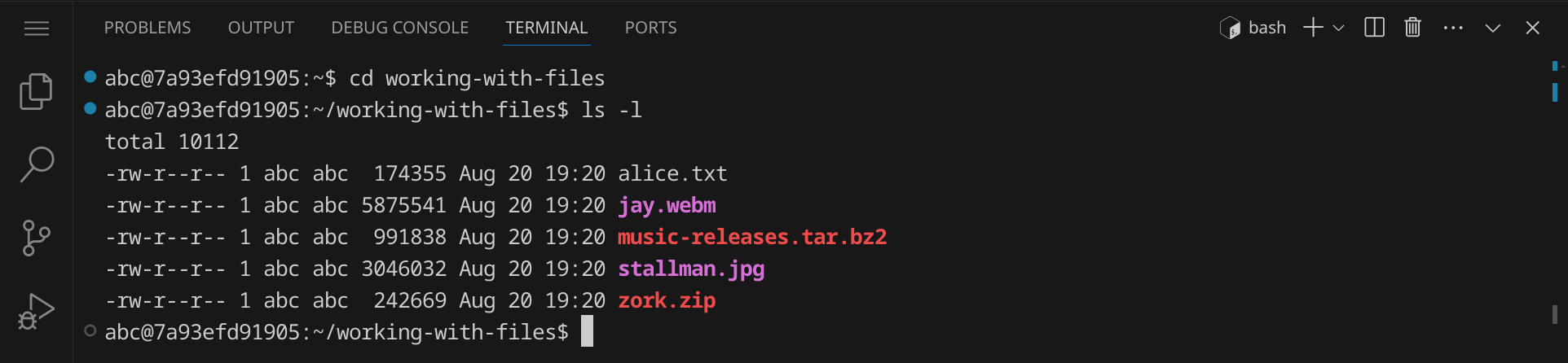
ls -la (für »long all«) anzeigen lassen kannst. Versteckte Dateien beginnen unter Linux mit einem Punkt.
Gib nun den Befehl file * ein und drücke die Eingabetaste. Der Stern * ist ein Platzhalter, der für alle Dateien im aktuellen Verzeichnis steht. Der Befehl file zeigt den Dateityp einer Datei an und mit file * können wir also den Dateityp aller Dateien im aktuellen Verzeichnis anzeigen.
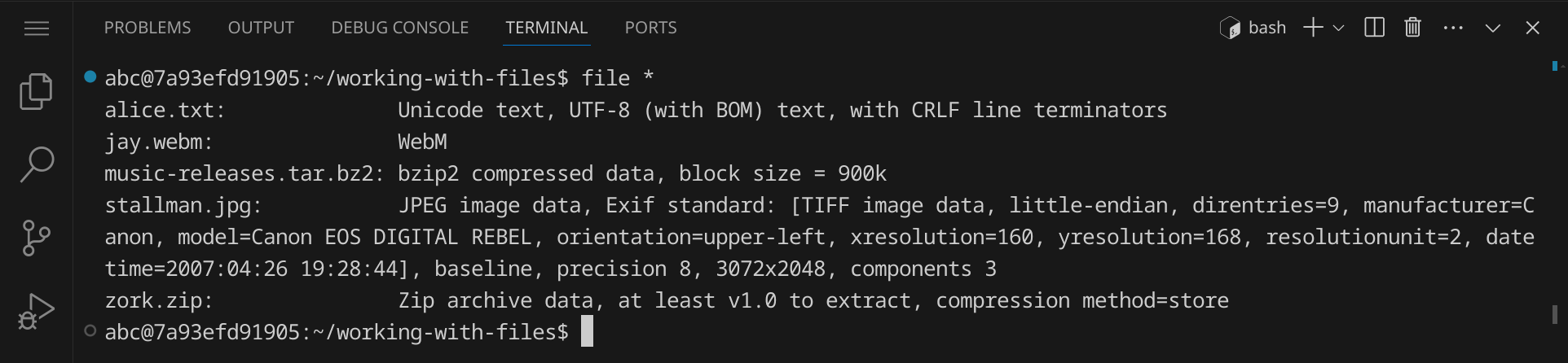
Oft ist der Dateityp einer Datei schon anhand der Dateiendung zu erkennen. Das Programm file kann jedoch auch den Dateityp von Dateien ohne Dateiendung bestimmen und gibt einige zusätzliche Informationen aus.
Wir sehen die folgenden Dateien:
alice.txt |
eine normale Textdatei |
jay.webm |
eine Videodatei im WebM-Format |
music-releases.tar.bz2 |
ein komprimiertes Archiv im Bzip2-Format |
stallman.jpg |
eine Bilddatei im JPEG-Format mit sehr vielen Metadaten |
zork.zip |
ein komprimiertes Archiv im ZIP-Format |
In den folgenden Abschnitten wirst du weitere Befehle kennenlernen und anhand dieser Dateien ausprobieren können.
cat, less und hd kennen.
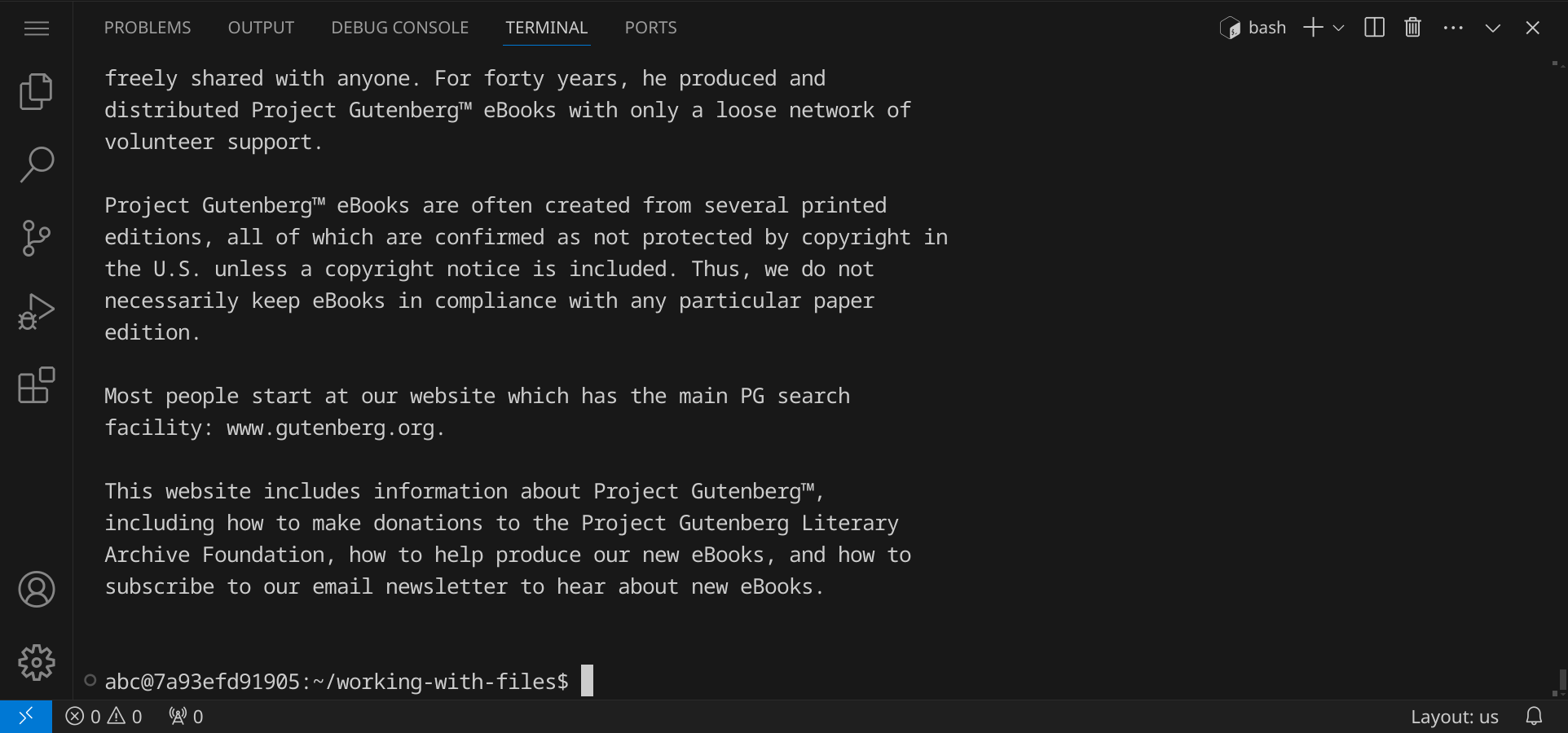
Gib cat alice.txt ein und drücke die Eingabetaste. Der Befehl cat steht für »concatenate« und zeigt den Inhalt einer Datei an. Die Datei alice.txt enthält den Text des Buches »Alice im Wunderland« von Lewis Carroll. Der Text stammt von Project Gutenberg und da der ganze Text im Terminal an dir vorbei rauscht, siehst du auch nur die letzten Zeilen, die auf die Quelle des Textes hinweisen:
Um den Text Seite für Seite zu lesen und die Möglichkeit zum scrollen zu bekommen, kannst du den Befehl less verwenden. Gib less alice.txt ein und drücke die Eingabetaste. Der Befehl less zeigt den Inhalt einer Datei an und ermöglicht es dir, durch den Text zu scrollen. Du kannst die Pfeiltasten ←↑→↓ oder Bild↑Bild↓ sowie Pos1 und Ende verwenden, um durch den Text zu navigieren. Drücke die Taste Q (für »quit«), um less zu beenden.
Wenn wir less mit den anderen Dateien, die keinen Textdateien sind, verwenden, sehen wir, dass less nicht für alle Dateitypen geeignet ist. Gib less jay.webm ein und drücke die Eingabetaste. Du siehst eine Warnung, dass jay.webm keine Textdatei ist und deshalb vermutlich nicht korrekt angezeigt werden kann:

Wenn du hier mit y bestätigst, wird der Inhalt der Datei trotzdem angezeigt, aber es wird nicht lesbar sein:
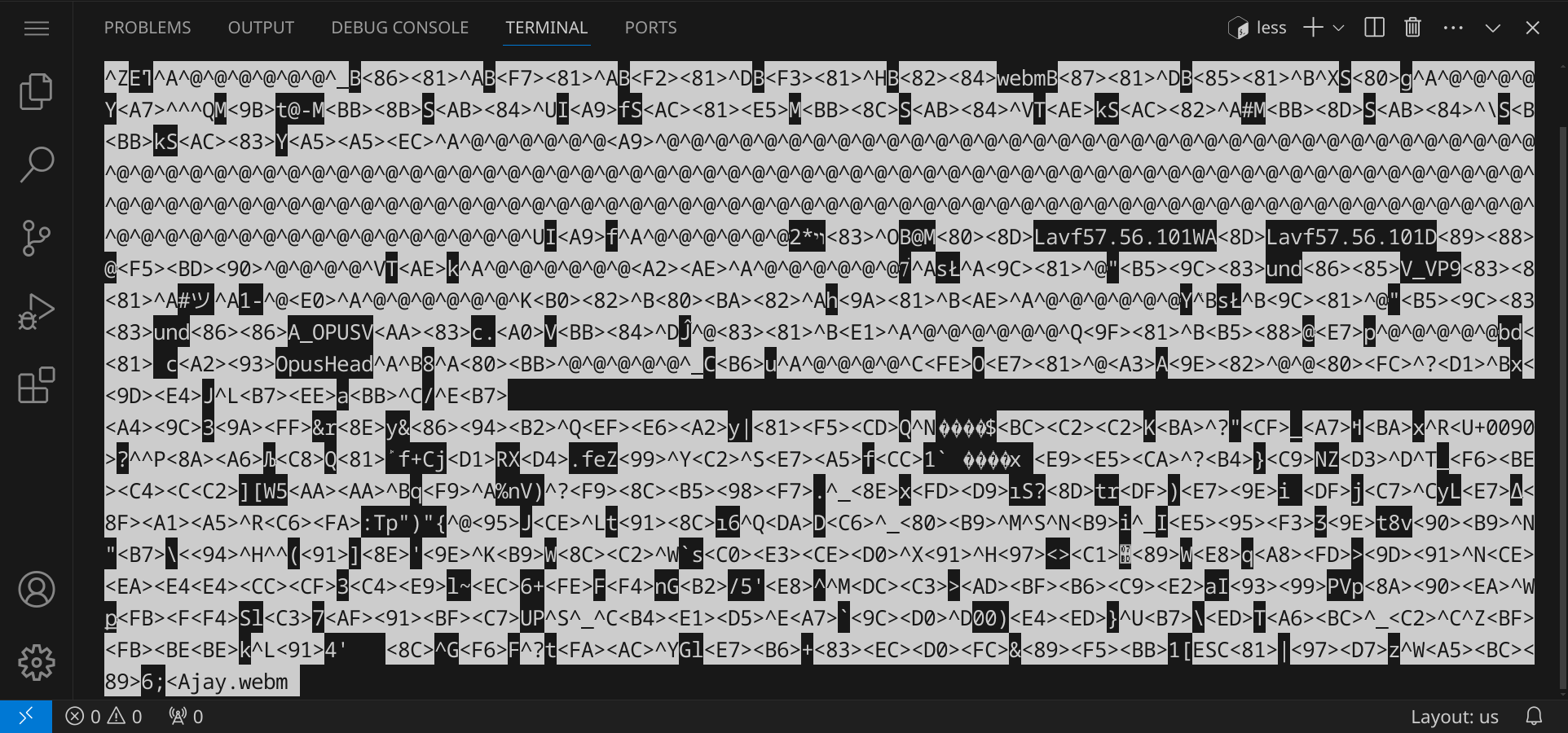
Drücke die Taste Q, um less zu beenden.
Mit less stallman.jpg siehst du, dass less bei Bildern zumindest ein paar Metadaten anzeigen kann:

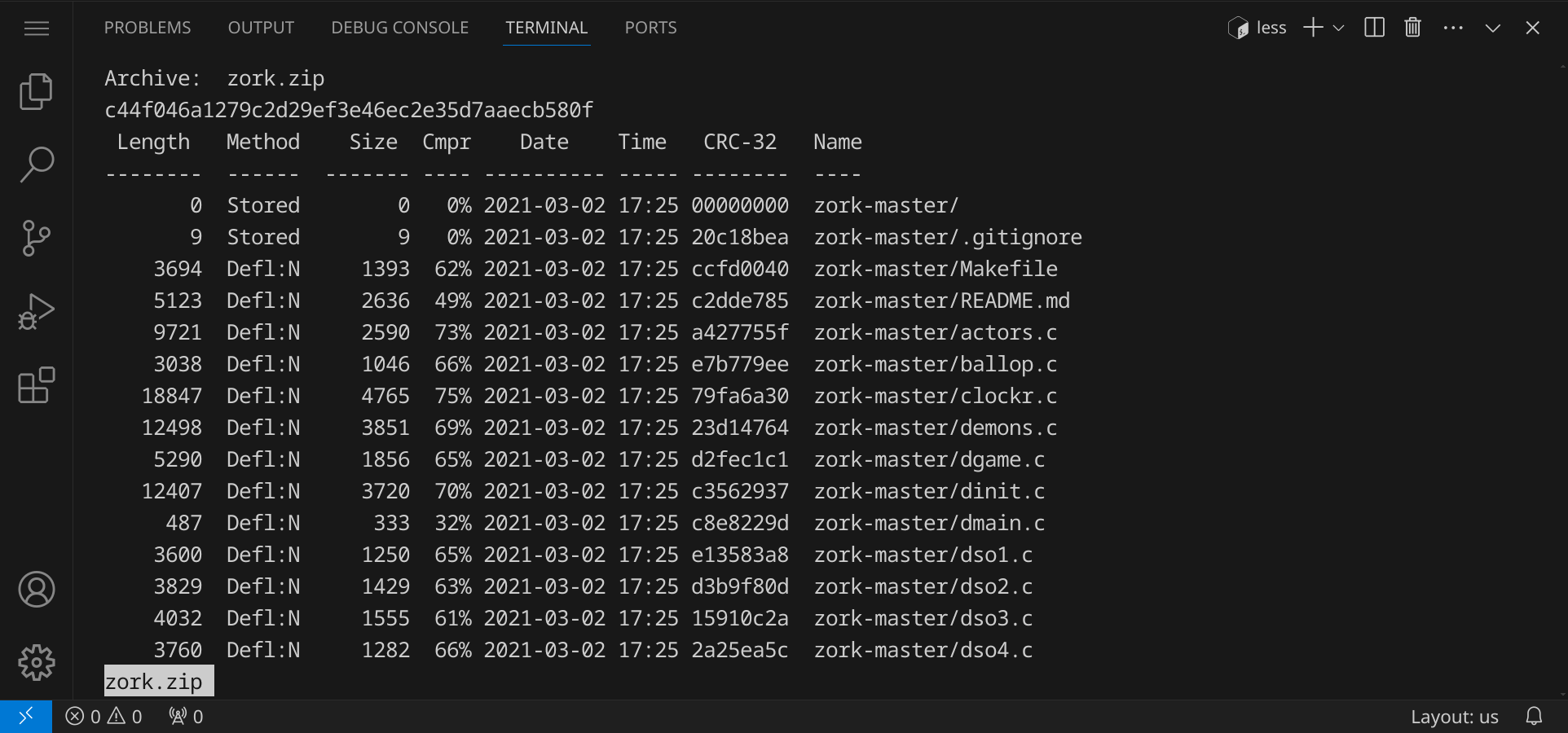
Wenn du less auf die Archivdateien anwendest, bekommst du eine Vorschau der Dateien, die sich im Archiv befinden:
Um die einzelnen, tatsächlichen Bytes zu sehen, die in einer Datei gespeichert sind, kannst du den Befehl hd verwenden. Gib hd alice.txt | less ein und drücke die Eingabetaste. Der Befehl hd steht für »hexdump« und zeigt den Inhalt einer Datei in hexadezimaler Darstellung an. Du siehst die Bytes, die in der Datei gespeichert sind, und kannst so den Inhalt der Datei auf Byte-Ebene analysieren. Du kannst nun durch die Ausgabe von hd navigieren. Drücke die Taste Q, um das Programm zu beenden.
| kann man mehrere Befehle in einer »Pipeline« miteinander verknüpfen. Die Ausgabe des ersten Befehls wird als Eingabe des zweiten Befehls verwendet. So können wir z. B. die Ausgabe von hd an die Eingabe von less weiterleiten, um die Ausgabe von hd seitenweise zu betrachten. Auf diese Weise lassen sich viele Befehle miteinander kombinieren.
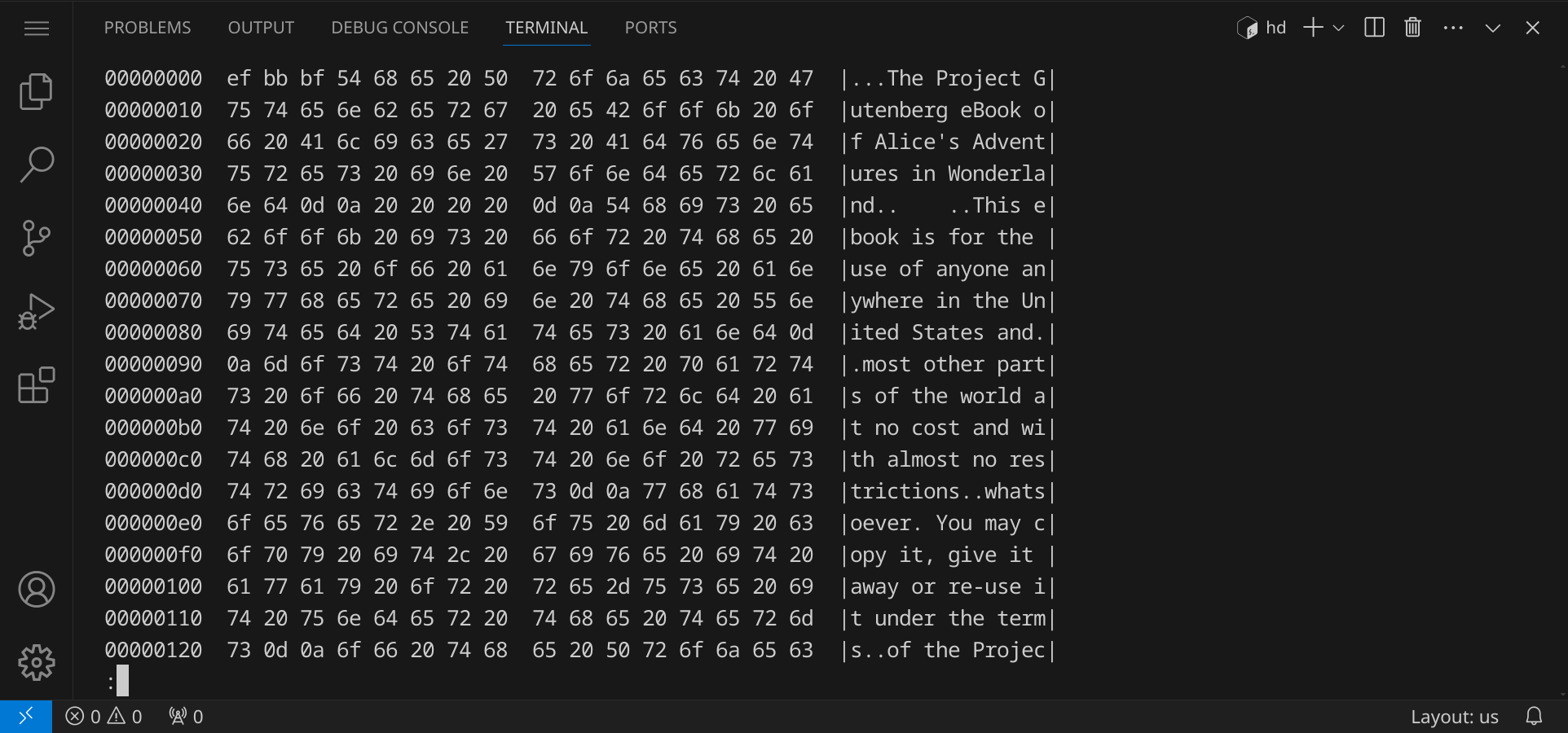
Im Hexdump siehst du immer 16 Bytes in einer Zeile. Die erste Spalte zeigt den Offset in der Datei an (hexadezimal), die zweite Spalte zeigt die hexadezimalen Werte der 16 Bytes an und die dritte Spalte zeigt die ASCII-Zeichen an, die den hexadezimalen Werten entsprechen. Wenn ein Byte nicht druckbar ist, wird ein Punkt angezeigt.
In der folgenden Tabelle siehst du, welche Werte welchem ASCII-Zeichen entsprechen:
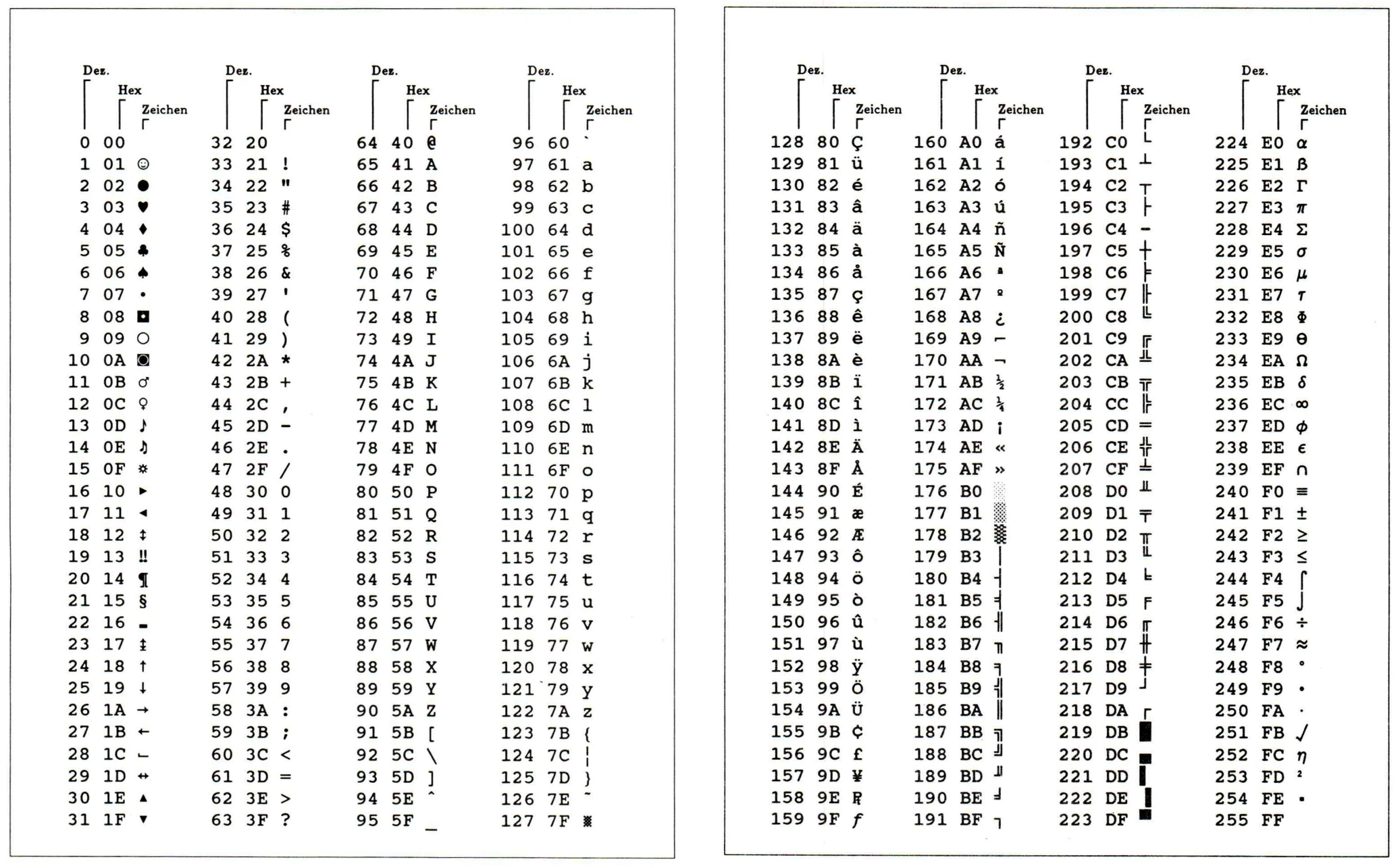
Wenn du dir den Hexdump genau anschaust, findest du z. B. Leerzeichen (20) und Zeilenumbrüche (0d 0a), auch CRLF genannt. Hieran erkennst du, dass es sich um eine Windows-Textdatei handelt. Linux-Textdateien verwenden nur ein LF (0a) als Zeilenumbruch (trotzdem kann Linux mit beiden Arten von Textdateien umgehen).
Du kannst die Dateien natürlich auch in Visual Studio Code öffnen, indem du die linke Seitenleiste mit StrgB einblendest und dann auf »Open Folder« klickst (oder einfach die Abkürzung StrgK+O verwendest). Wähle das Verzeichnis working-with-files aus und klicke auf »OK«.

Links siehst du jetzt die Dateien und kannst sie (bis auf die Archivdateien) öffnen, um ihren Inhalt zu sehen.
Schließe anschließend wieder alle Dateien und öffne das Terminal, um mit den nächsten Befehlen fortzufahren.
Nachdem wir uns nun einen Überblick verschafft und uns die Dateien angeschaut haben, werden wir im nächsten Abschnitt sehen, wie wir Dateien erstellen und bearbeiten können.
touch, nano, vim und emacs kennen.
Gib den Befehl touch hello.txt ein und drücke die Eingabetaste. Der Befehl touch erstellt eine leere Datei mit dem angegebenen Namen. Gib ls -l ein, um zu sehen, dass die Datei hello.txt erstellt wurde:
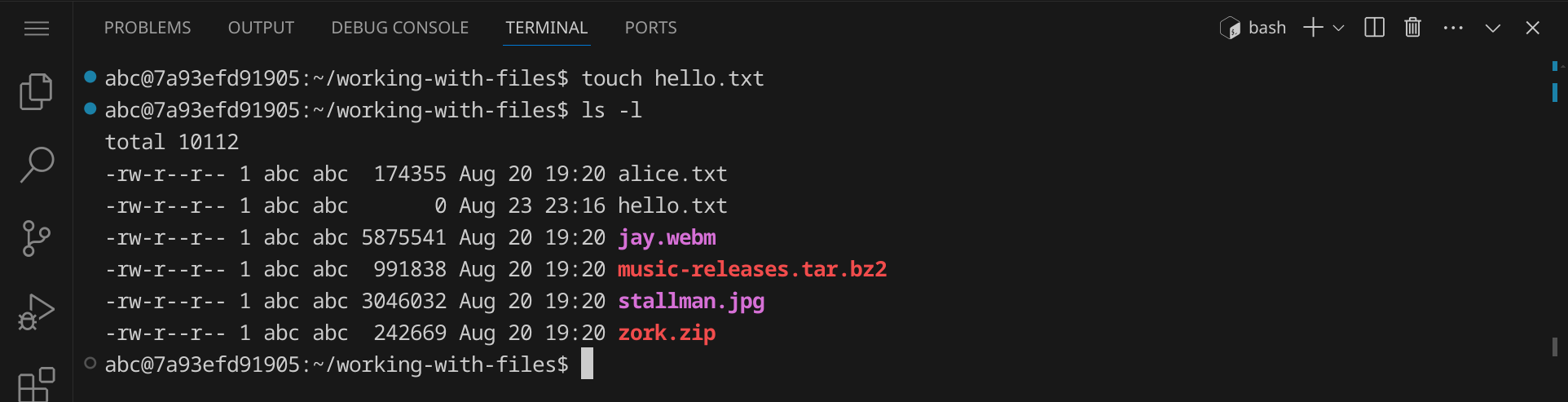
Da die Datei keinen Inhalt hat, beträgt ihre Größe erwartungsgemäß 0 Byte. Wenn du nach einer oder mehreren Minuten noch einmal touch hello.txt eingibst, siehst du, dass sich danach der Zeitstempel der Datei geändert hat:

Der Befehl touch wird oft verwendet, um den Zeitstempel einer Datei zu aktualisieren, ohne den Inhalt zu verändern. Wenn die Datei nicht existiert, wird sie erstellt.
Es gibt verschiedene Text-Editoren für Linux, mit denen du Dateien im Terminal bearbeiten kannst. Die gebräuchlichsten Editoren sind nano, vim und emacs. nano ist der einfachste Editor und wird oft für Anfänger empfohlen. vim und emacs sind mächtige Editoren, die viele Funktionen bieten, aber auch eine steile Lernkurve haben. Wir werden uns alle drei Editoren kurz ansehen.
nano
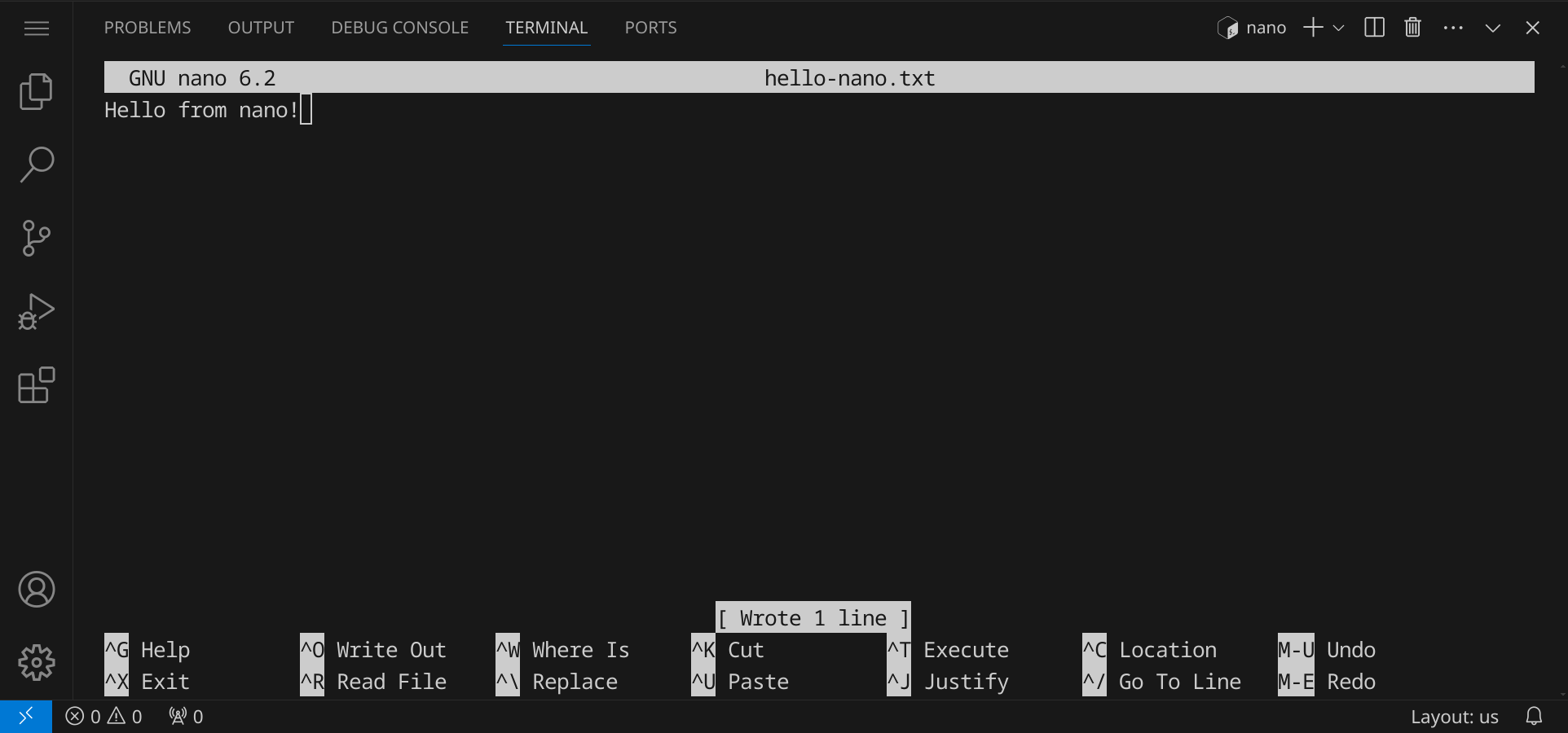
Gib den Befehl nano hello-nano.txt ein, um eine neue Datei zu öffnen. Du kannst nun Text eingeben und relativ intuitiv im Text navigieren. Wenn du fertig bist, speichere deinen Text mit StrgO (für »write out«) und bestätige mit der Eingabetaste. Beende nano mit StrgX (für »exit«).
vim
Gib den Befehl vim hello-vim.txt ein, um eine neue Datei zu öffnen. vim hat verschiedene Modi, die du mit der Taste Esc wechseln kannst. Im Befehlsmodus kannst du Befehle eingeben, um Text zu bearbeiten. Im Einfügemodus kannst du Text eingeben. Um in den Einfügemodus zu wechseln, drücke i (für »insert«). Um den Eingabemodus zu verlassen und zum Befehlsmodus zurückzukehren, drücke Esc. Um vim zu beenden, wechsle in den Befehlsmodus und gib :q ein. Wenn du deine Änderungen speichern möchtest, gib :w ein. Wenn du vim beenden und deine Änderungen speichern möchtest, gib :wq ein.
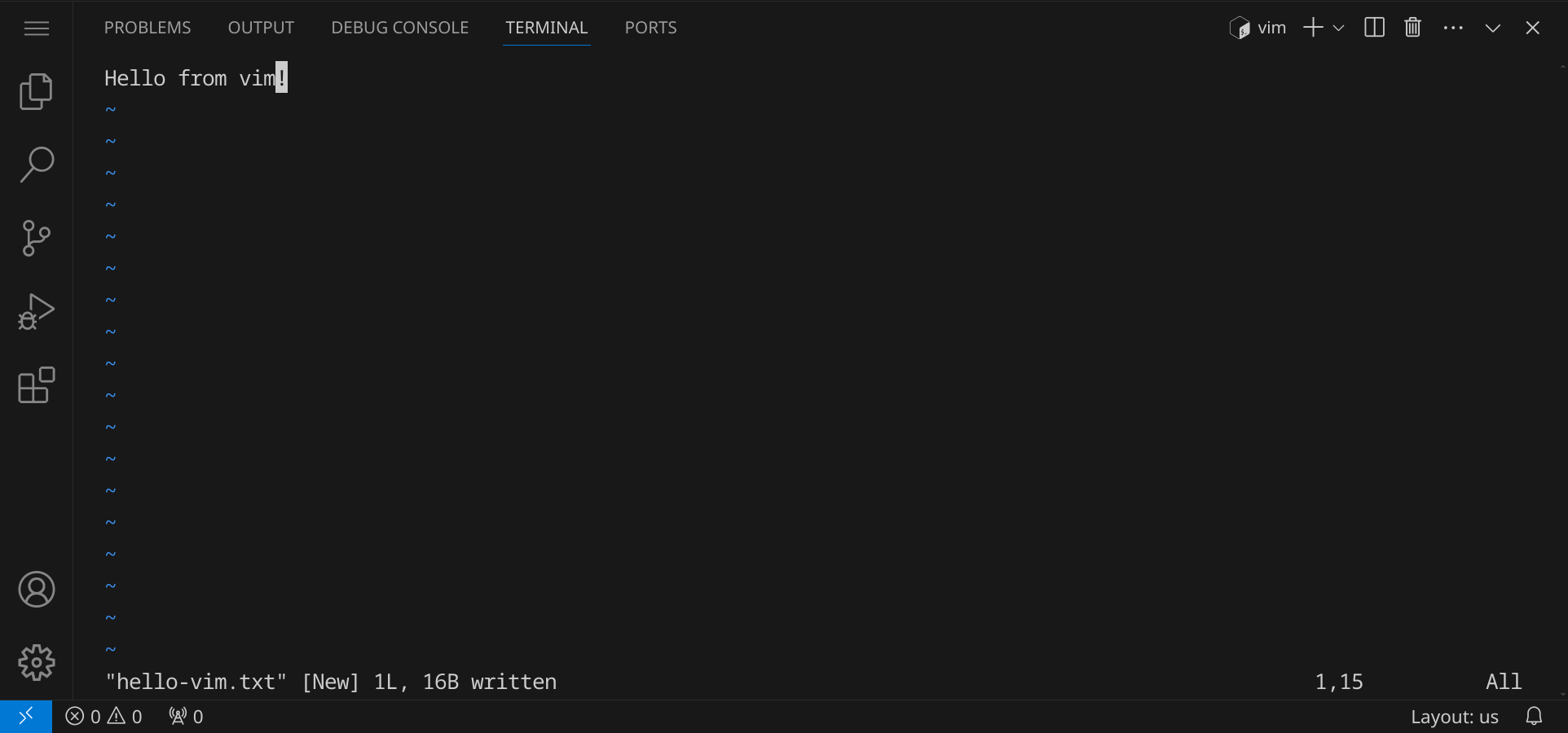
Für die oben stehende Eingabe musst du also folgende Tasten drücken:
vim zu beendenFalls du mehr über vim lernen und den Umgang mit diesem Editor trainieren möchtest, kannst du den Befehl vimtutor im Terminal eingeben, um ein interaktives Tutorial zu starten, für das du ca. 30 Minuten einplanen solltest:
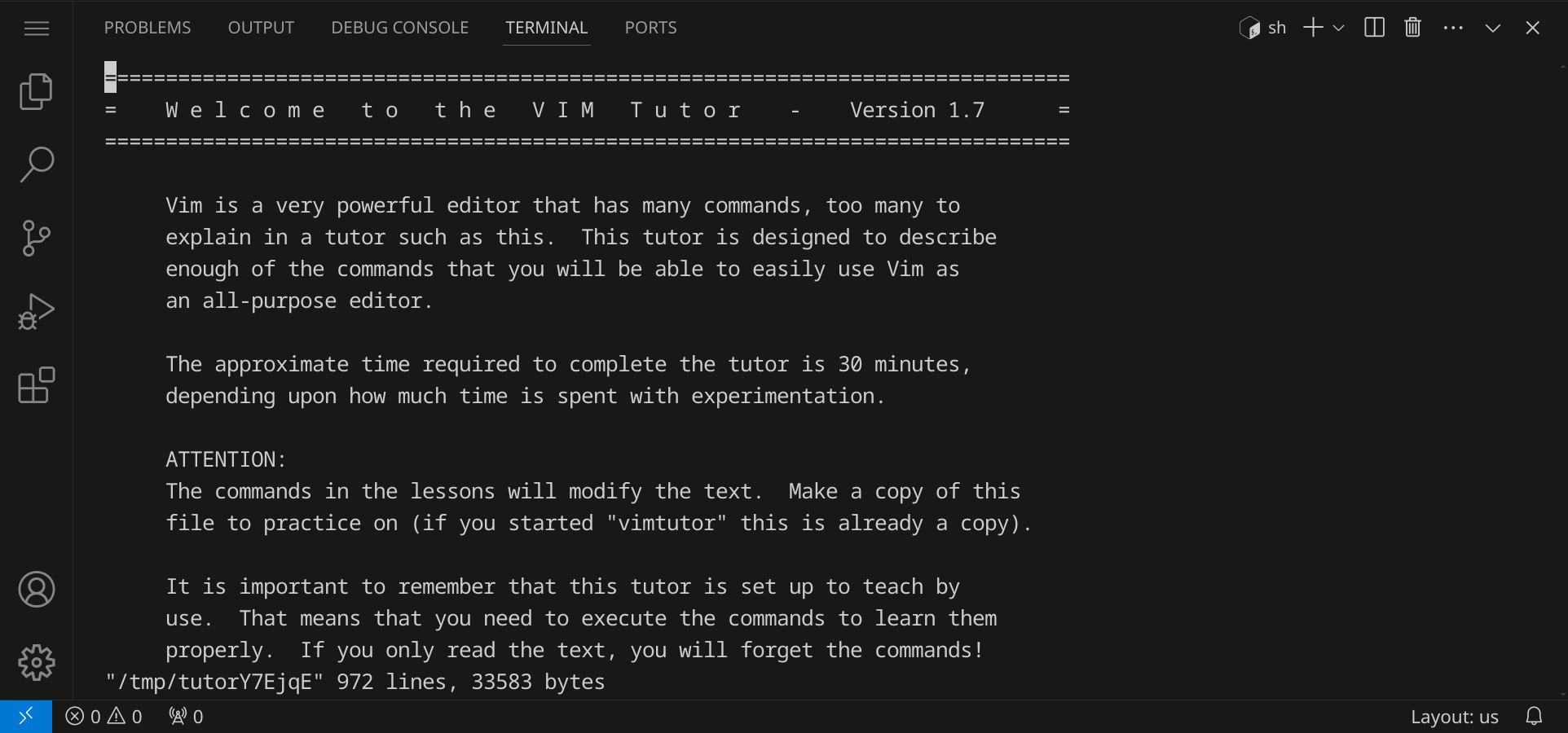
vimtutor lässt sich, genau wie vim selbst, mit :, q und Enter beenden.
emacs
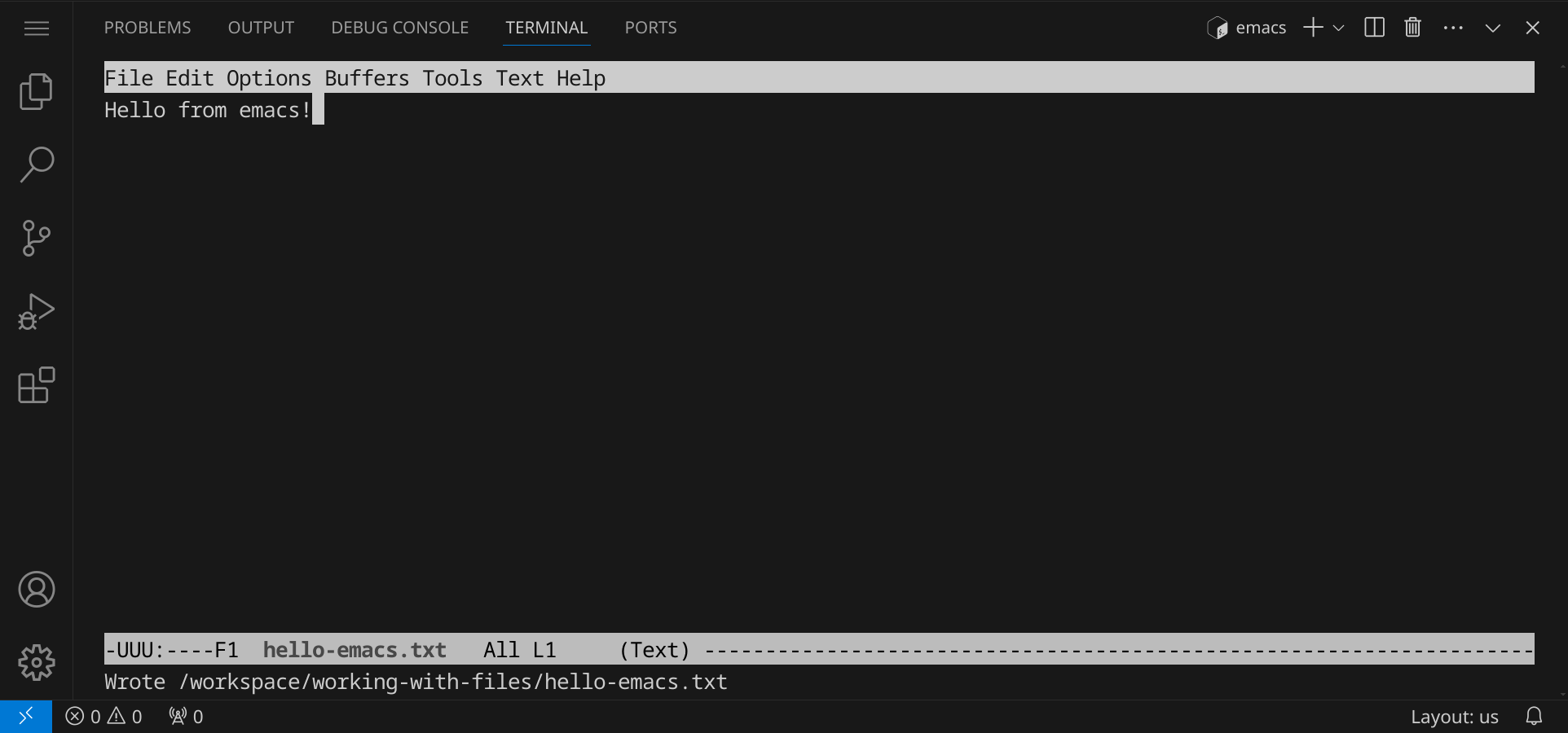
Gib den Befehl emacs hello-emacs.txt ein, um eine neue Datei zu öffnen. Im Gegensatz zu vim kannst du hier einfach anfangen, Text einzugeben. Wenn du fertig bist, speichere deine Änderungen mit StrgX und dann StrgS (für »save«). Um emacs zu beenden, drücke StrgX und dann StrgC.
wc, grep, sort, uniq, head und tail kennen.
Gib den Befehl wc alice.txt ein und drücke die Eingabetaste. Der Befehl wc steht für »word count« und zeigt dir die Anzahl der Zeilen, Wörter und Bytes in einer Datei an:

Die Datei alice.txt enthält also 3.756 Zeilen, 29.564 Wörter und 174.355 Bytes. Oft wird wc dazu verwendet, um die Anzahl der Zeilen in einer Datei zu zählen. Wenn du nur die Anzahl der Zeilen wissen möchtest, kannst du den Befehl wc -l alice.txt (-l für »lines«) verwenden:

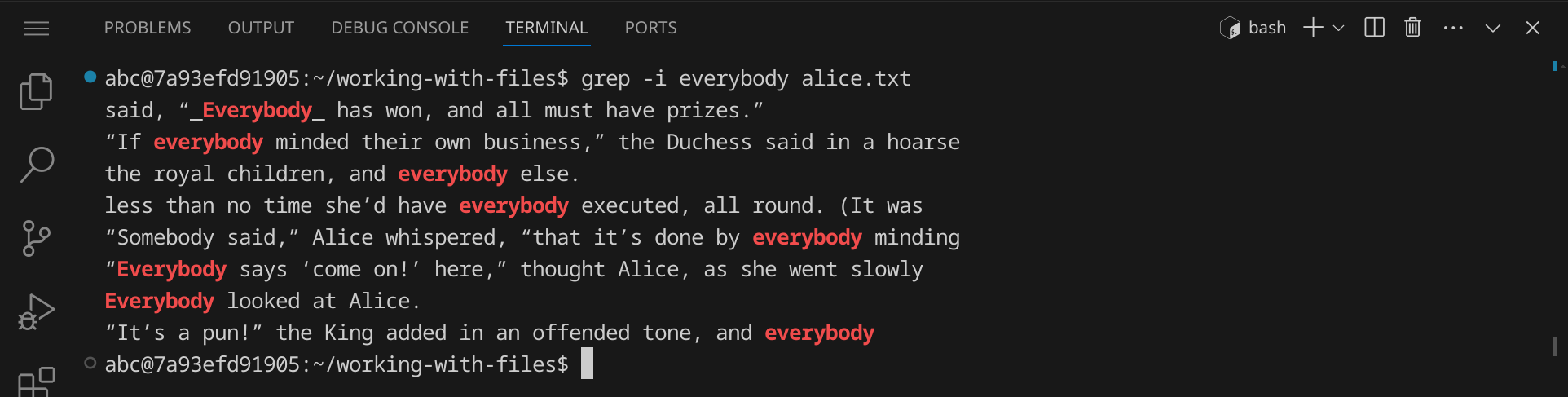
Verwende grep, um nach einem bestimmten Muster in einer Datei zu suchen. Gib grep everybody alice.txt ein und drücke die Eingabetaste. Der Befehl grep sucht nach dem Muster »everybody« in der Datei alice.txt und zeigt die Zeilen an, in denen das Muster gefunden wurde:

Mit der Option -i können wir grep anweisen, die Groß- und Kleinschreibung zu ignorieren. Gib grep -i everybody alice.txt ein und drücke die Eingabetaste:
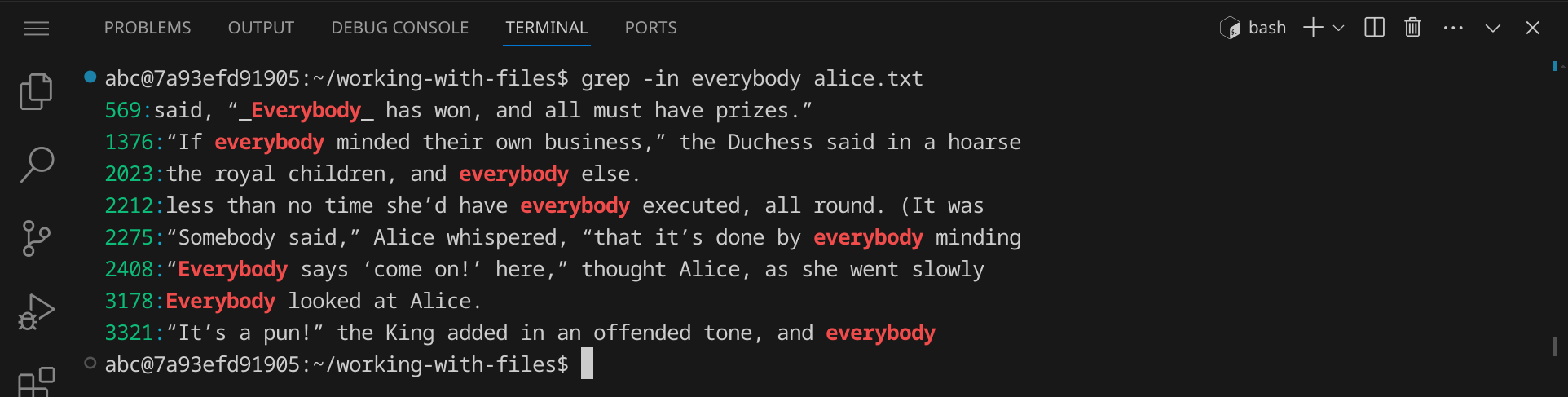
Wir haben nun ein paar weitere Stellen gefunden. Wenn du die Zeilennummer sehen möchtest, in denen das Muster gefunden wurde, kannst du die Option -n verwenden:
grep ist ein sehr mächtiges Programm mit einer Vielzahl von Optionen. Du kannst z. B. reguläre Ausdrücke verwenden, um nach komplexeren Mustern zu suchen. Gib man grep ein, um die manpage von grep zu lesen und mehr über die verschiedenen Optionen zu erfahren.
Wir wollen nun alle Wörter aus der Datei alice.txt extrahieren. Gib dazu den folgenden Befehl ein:
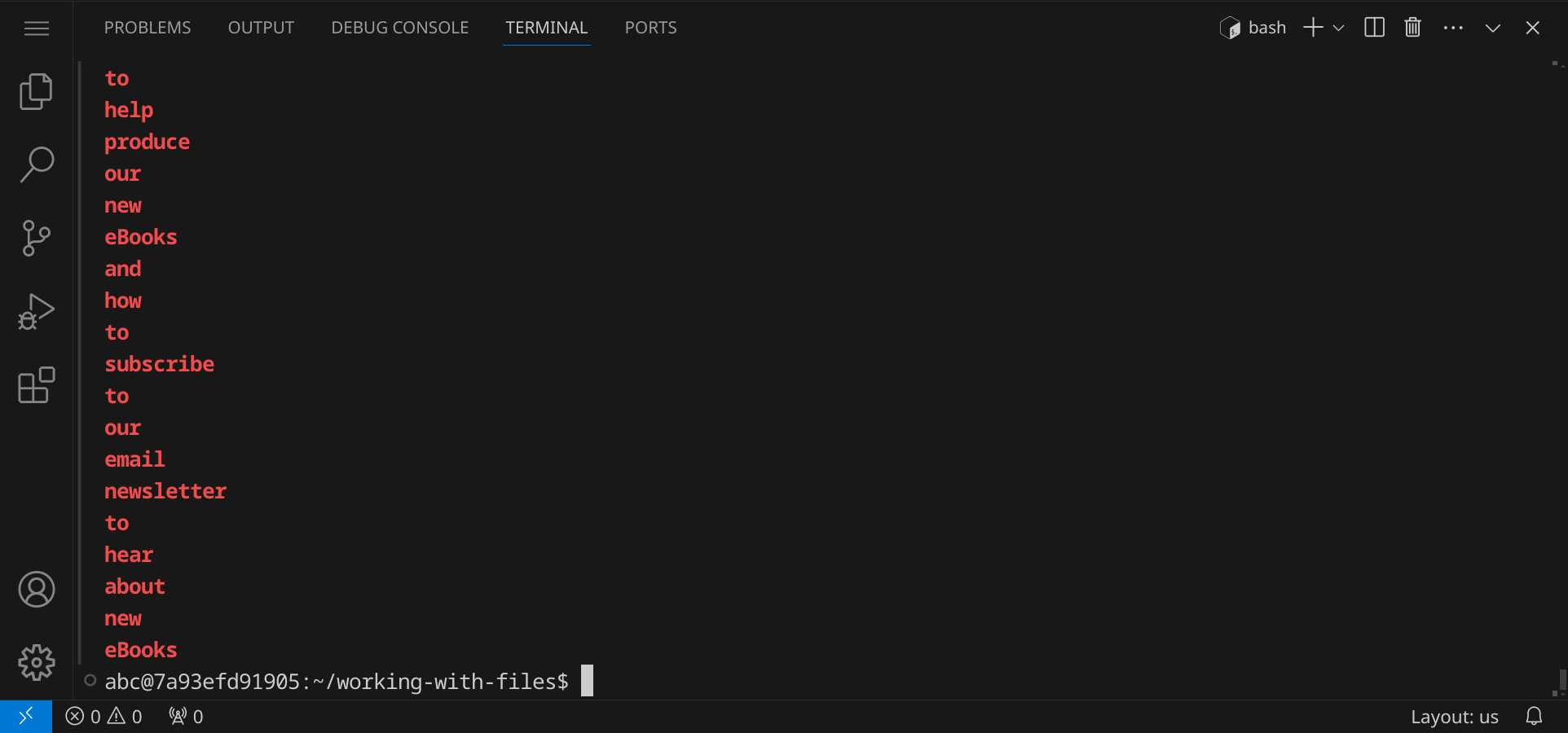
grep -o -E "[A-Za-z]+" alice.txt
Der reguläre Ausdruck [A-Za-z]+ sucht nach Wörtern, die aus Groß- und Kleinbuchstaben bestehen. Du siehst, wie der gesamte Text Wort für Wort ausgegeben wird:
| less anhängen.
Nutze sort, um die Ausgabe zu sortieren:
grep -o -E "[A-Za-z]+" alice.txt | sort
Jetzt sind die Wörter alphabetisch sortiert:

Um Duplikate zu entfernen, können wir uniq verwenden:
grep -o -E "[A-Za-z]+" alice.txt | sort | uniq
Dadurch wurden aufeinanderfolgende Duplikate entfernt und wir sehen nun eine alphabetisch sortierte Liste aller Wörter, die im Text vorkommen:

Allerdings gibt es hinsichtlich der Groß- und Kleinschreibung noch Duplikate (»you«, »You«, »YOU«). Um auch diese zu entfernen, können wir die Option -i von uniq verwenden (für »ignore case«):
grep -o -E "[A-Za-z]+" alice.txt | sort | uniq -i
Nun ist unsere Liste fertig:
Wir können nun die Anzahl der Wörter in der Liste zählen:
grep -o -E "[A-Za-z]+" alice.txt | sort | uniq -i | wc -l
Die Ausgabe zeigt, dass es 3.002 verschiedene Wörter in der Datei alice.txt gibt.

Wir können unser Ergebnis auch in einer Datei speichern, indem wir die Ausgabe der gesamten Pipeline in eine Datei umleiten:
grep -o -E "[A-Za-z]+" alice.txt | sort | uniq -i > words.txt

Es gibt noch zwei weitere Befehle, die nützlich sind, wenn man nur den Anfang oder das Ende einer Datei oder einer Ausgabe sehen möchte. Nutze head, um die ersten 10 Zeilen einer Datei oder einer Ausgabe zu sehen:
head words.txt
Analog dazu kannst du tail verwenden, um die letzten 10 Zeilen einer Datei oder einer Ausgabe zu sehen:
tail words.txt
tail wird in Verbindung mit der Option -f (für »follow«) oft verwendet, um eine Datei in Echtzeit zu beobachten. Wenn du z. B. eine Logdatei überwachen möchtest, kannst du tail -f logfile.log verwenden, um die letzten Zeilen der Datei anzuzeigen und neue Zeilen anzuzeigen, sobald sie hinzugefügt werden.
tree, unzip, tar, gzip und bzip2 kennen.
Gib den Befehl tree ein, um eine Baumstruktur des aktuellen Verzeichnisses anzuzeigen.
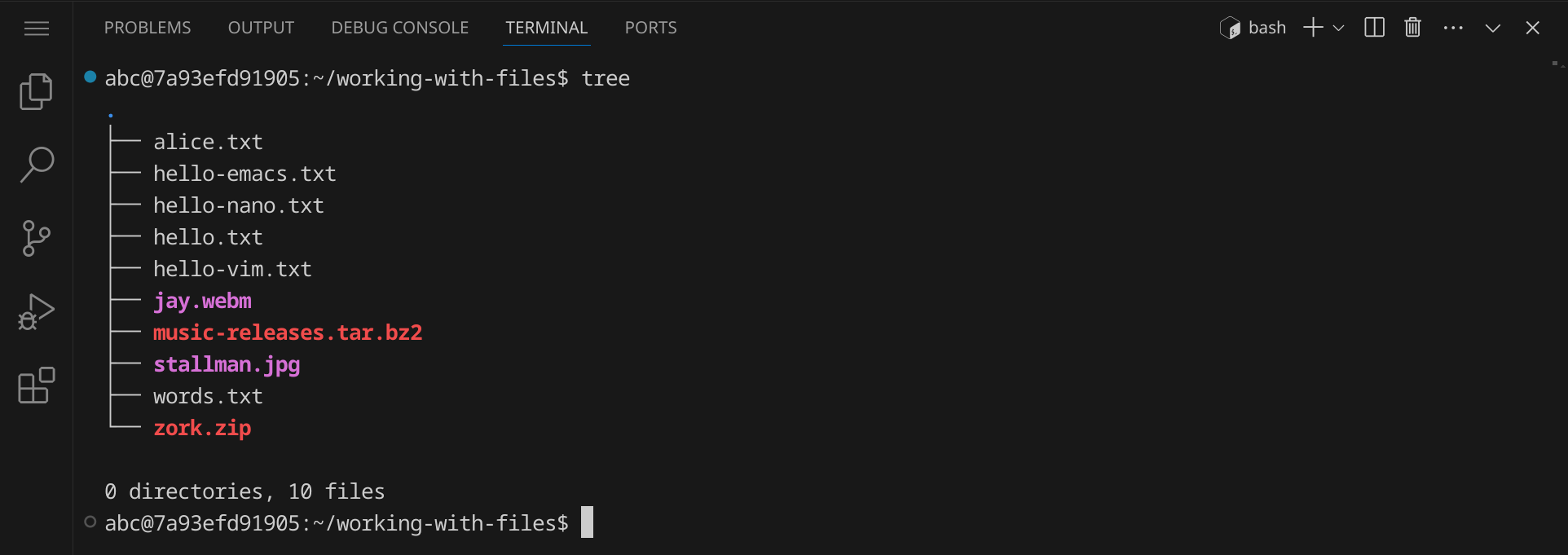
Im Moment unterscheidet sich Ausgabe von tree noch nicht sehr von der Ausgabe von ls. Das liegt daran, dass wir uns in einem flachen Verzeichnis ohne Unterverzeichnisse befinden. Wenn wir uns in einem tiefer verschachtelten Verzeichnis befinden, wird die Ausgabe von tree nützlicher.
Nutze unzip, um das Archiv zork.zip zu entpacken:
unzip zork.zip
unzip entpackt alle Dateien aus dem Archiv zork.zip in das aktuelle Verzeichnis.
Wenn du nun wieder tree eingibst und nach oben scrollst, siehst du, dass das Verzeichnis zork-master mit einigen Dateien hinzugefügt wurde:
Wechsle in das Verzeichnis zork-master und gib ls ein, um zu sehen, was sich darin befindet:
cd zork-master ls

Lass dir den Inhalt der Datei readme.txt anzeigen:
cat readme.txt

Es handelt sich also um ein Spiel. Da es in der Programmiersprache C geschrieben ist und es ein Makefile gibt, können wir es leicht kompilieren, um ein ausführbares Programm zu erhalten.
make
Ein paar Sekunden und wenige Warnungen später haben wir ein ausführbares Programm namens zork:
Du kannst das Spiel starten, indem du ./zork eingibst:

zork eingeben, um das Spiel zu starten, da das aktuelle Verzeichnis nicht im Suchpfad enthalten ist. Du musst also explizit angeben, dass du die Datei zork im aktuellen Verzeichnis (welches mit . bezeichnet wird) ausführen möchtest.
Falls du Zork beenden möchtest, bevor du das Spiel durchgespielt hast, kannst du dies durch die Eingabe von quit erreichen.
Verlasse nun wieder das Verzeichnis zork-master, indem du cd .. eingibst. Wir werden nun das Archiv music-releases.tar.bz2 entpacken:
tar xvf music-releases.tar.bz2
Nach dem Entpacken siehst du, dass ein neues Verzeichnis music-releases hinzugefügt wurde. Die Ausgabe von tree zeigt dir die Baumstruktur des Verzeichnisses:
Es handelt sich um ein Verzeichnis mit mehreren Unterverzeichnissen, in dem sich Alben und Singles / EPs verschiedener Künstlerinnen und Künstler bzw. Bands, nach Land und Jahr sortiert, befinden.
Wechsle in das Verzeichnis und lass dir den Inhalt anzeigen:
cd music-releases ls -l
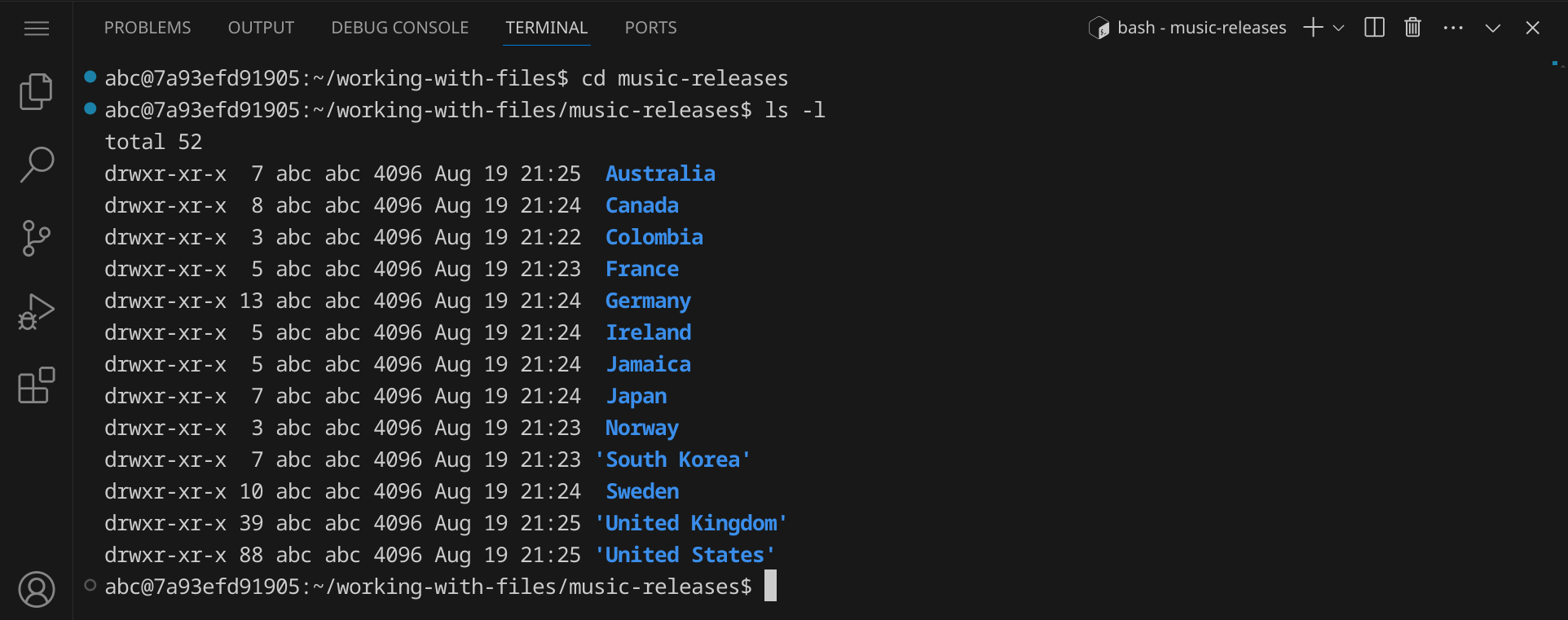
Dir fällt sicherlich auf, dass einige Verzeichnisnamen in Anführungszeichen stehen. Das liegt daran, dass sie Leerzeichen enthalten. Wenn du einen Datei- oder Verzeichnisnamen als Argument an einen Befehl übergibst und der Name Leerzeichen enthält, musst du den Namen in Anführungszeichen setzen, damit der Befehl den Namen als ein Argument erkennt.
Wechsle in das Verzeichnis Japan/Radwimps (verwende wie immer die Tab-Taste) und lass dir den Inhalt anzeigen:
cd Japan/Radwimps/ ls -l

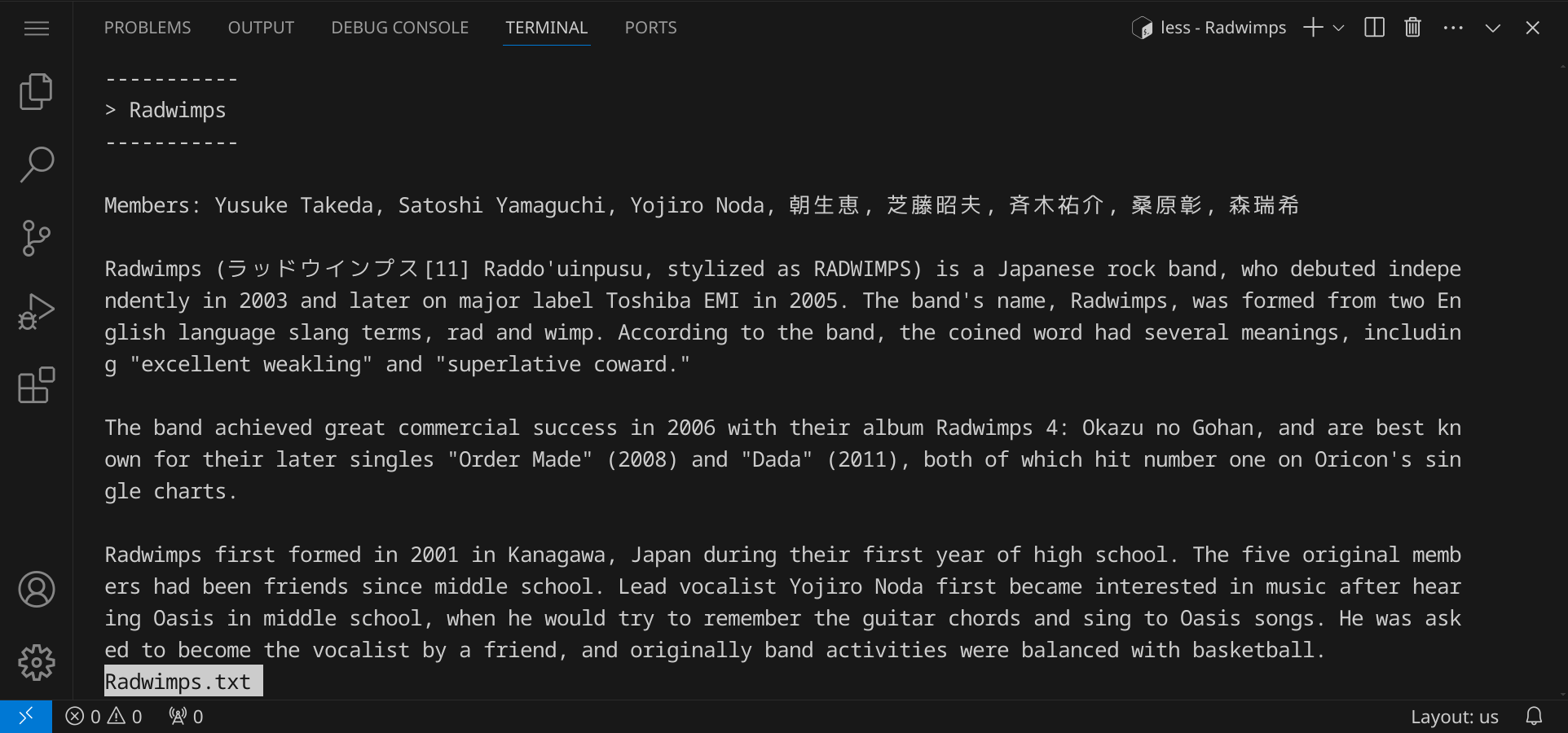
Eine kurze Information zur Geschichte der Band findest du in der Datei Radwimps.txt, die du dir mit less anzeigen lassen kannst:
less Radwimps.txt
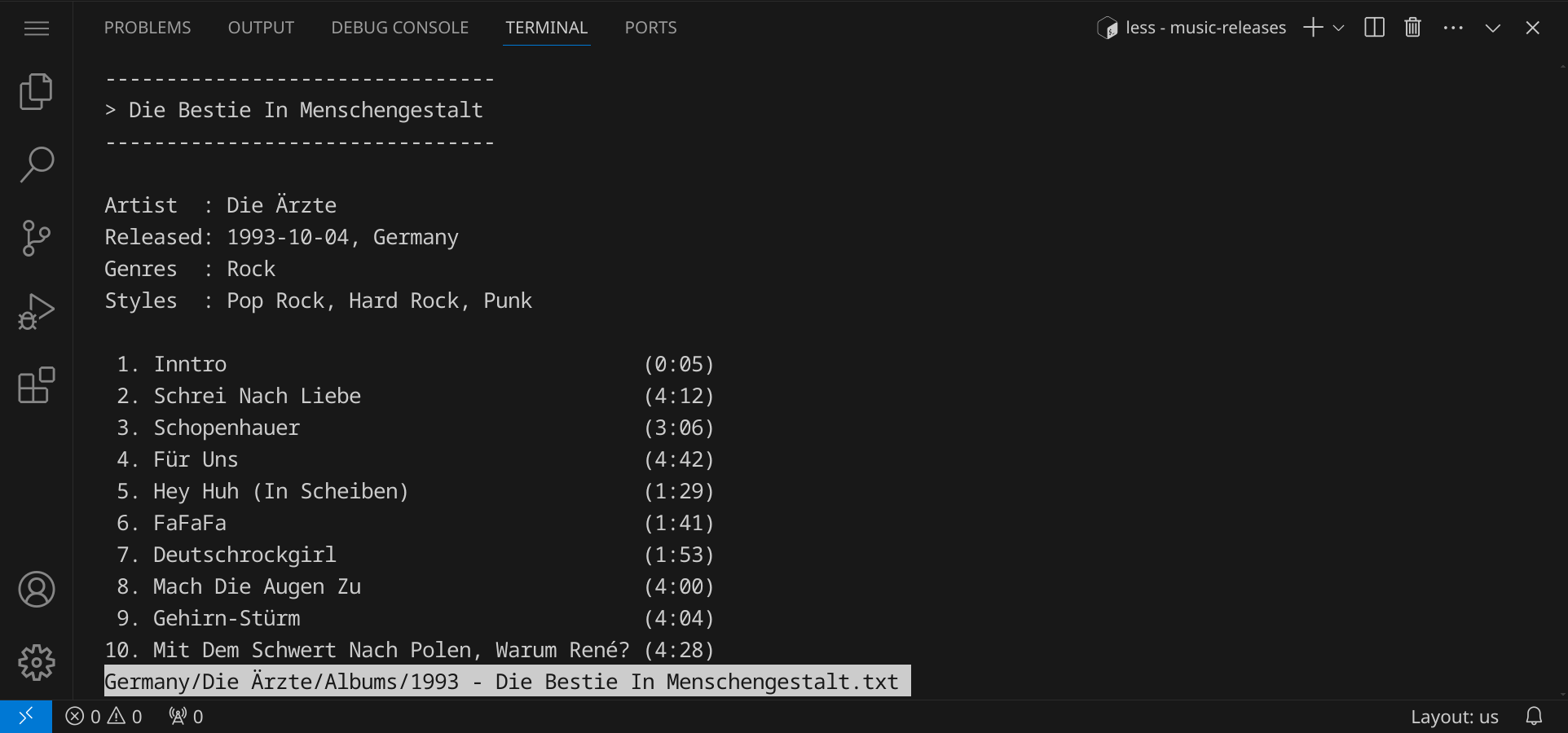
Schau auch in ein paar Alben rein, um ein Gefühl für die Tab-Ergänzung zu bekommen:
less Albums/2016\ -\ 君の名は。.txt

Gehe nun wieder ins Verzeichnis working-with-files zurück und lass dir die Größe der Datei alice.txt anzeigen:
cd ~/working-with-files ls -l alice.txt

Die Datei ist 174.355 Bytes groß. Wir können sie komprimieren, um Speicherplatz zu sparen. Dazu verwenden wir gzip:
gzip alice.txt ls -l alice.txt.gz
gzip hat die Datei alice.txt komprimiert und in die Datei alice.txt.gz umgewandelt. Die Datei ist jetzt nur noch 61.204 Bytes groß und belegt damit nur noch 35% des ursprünglichen Speicherplatzes:

Um die Datei wieder zu entpacken, verwenden wir gzip -d:
gzip -d alice.txt.gz
Die Option -d steht für »decompress« und entpackt die Datei alice.txt.gz wieder in die Datei alice.txt. Wenn du dir die Größe der Datei alice.txt ansiehst, wirst du feststellen, dass sie wieder 174.355 Bytes groß ist:

Wir können die Datei auch mit bzip2 komprimieren:
bzip2 alice.txt ls -l alice.txt.bz2

Wie du siehst, hast bzip2 eine noch kleinere Datei erzeugt, die nur 48.925 Bytes groß ist und somit nur noch 28% des ursprünglichen Speicherplatzes belegt. Um die Datei wieder zu entpacken, verwenden wir bzip2 -d:
bzip2 -d alice.txt.bz2 ls -l alice.txt

Die Datei ist wieder 174.355 Bytes groß.
du und find kennen.
Gib den Befehl du -h ein und drücke die Eingabetaste. Der Befehl du steht für »disk usage« und zeigt dir die Größe eines Verzeichnisses an. Die Option -h steht für »human-readable« und zeigt die Größe in einer besser lesbaren Form an:
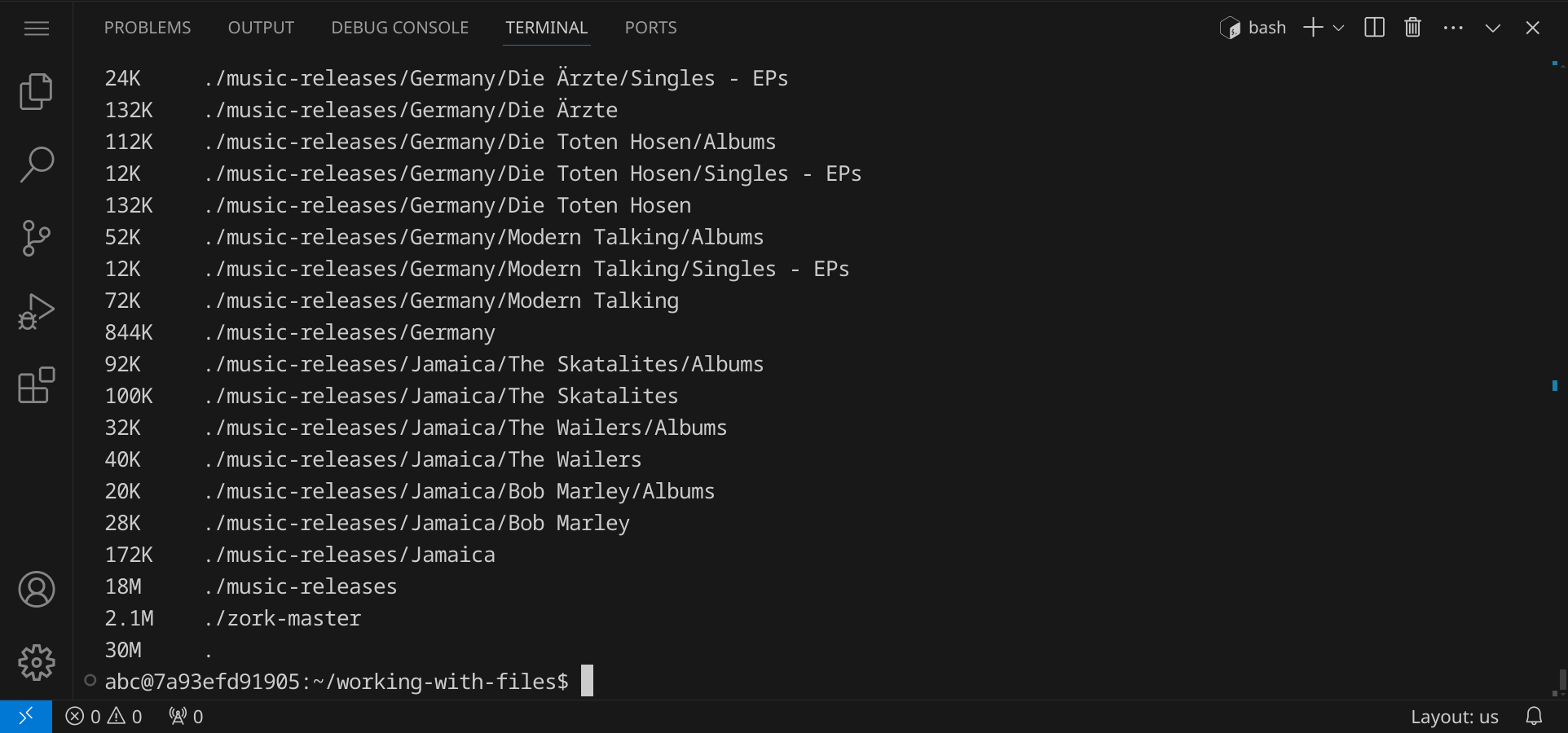
An der letzten Zeile erkennst du, dass das ganze Verzeichnis mit allen Unterverzeichnissen insgesamt 30 MB groß ist. Falls dich interessiert, wie viel Speicherplatz jedes einzelne Unterverzeichnis belegt, kannst du die Option -d (für »depth«) verwenden, um die Tiefe der Analyse anzugeben. Gib du -h -d 2 ein, um die Größen der Unterverzeichnisse bis zu einer Tiefe von 2 anzuzeigen:
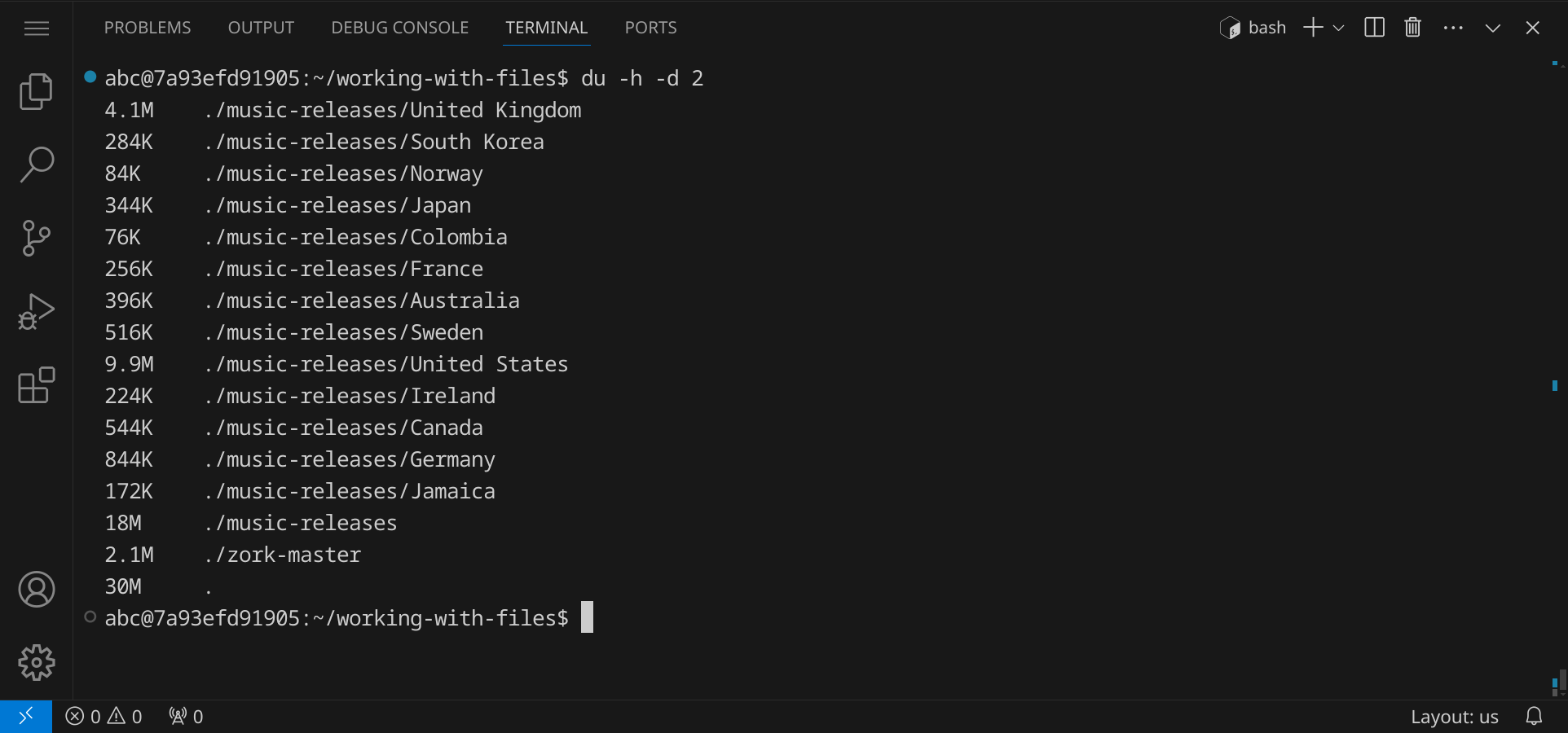
Man sieht hier sehr gut, dass die Unterverzeichnisse United States und United Kingdom am meisten Speicherplatz belegen.
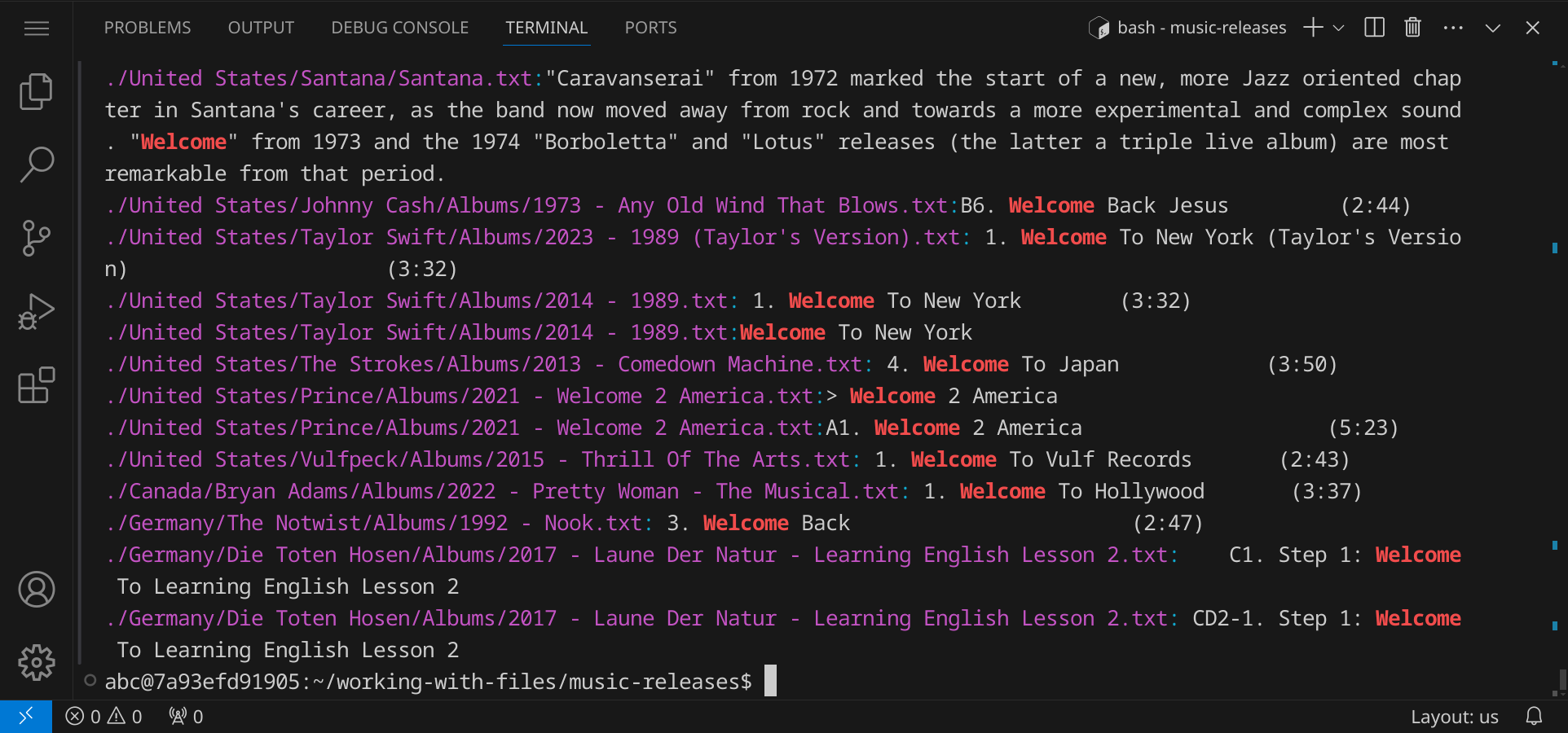
Wir können den Befehl grep, den wir weiter oben schon kennen gelernt haben, auch auf Verzeichnisse anwenden. Wechsle nun wieder ins Verzeichnis music-releases, und verwende den Befehl grep, um alle Dateien zu finden, die das Wort »welcome« enthalten:
cd music-releases grep -ri welcome .
Dabei stehen die Optionen -r für »recursive« (rekursiv) und -i für »ignore case« (Groß- und Kleinschreibung ignorieren). Der Punkt . steht für das aktuelle Verzeichnis. Es bedeutet also: untersuche alle Dateien im aktuellen Verzeichnis und allen Unterverzeichnissen. Wenn du den Befehl ausführst, siehst du alle Dateien, die das Wort »welcome« enthalten:
mkdir, cp, mv, rmdir und rm kennen.
Gehe nun wieder ins Verzeichnis working-with-files zurück:
cd ~/working-with-files
Nutze den Befehl mkdir, um ein neues Verzeichnis namens sandbox zu erstellen:
mkdir sandbox

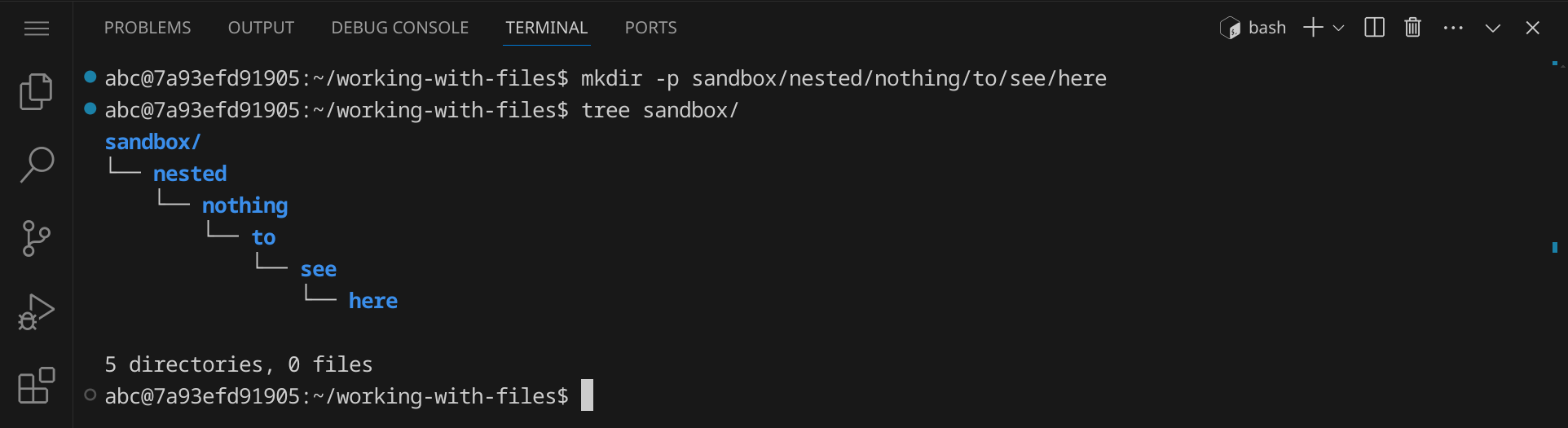
Wenn du ein Verzeichnis erstellen möchtest, das selbst ein Unterverzeichnis ist, kannst du die Option -p verwenden, um sicherzustellen, dass alle übergeordneten Verzeichnisse ebenfalls erstellt werden:
mkdir -p sandbox/nested/nothing/to/see/here
Nutze den Befehl cp, um Dateien zu kopieren. Der Befehl benötigt zwei Argumente: die Quelle und das Ziel.
Möglichkeit 1: eine Datei in ein anderes Verzeichnis kopieren
Du kannst eine Datei aus dem aktuellen Verzeichnis in ein anderes Verzeichnis kopieren. Kopiere die Datei jay.webm in das Verzeichnis sandbox:
cp jay.webm sandbox
Die Datei jay.webm wurde in das Verzeichnis sandbox kopiert:

Möglichkeit 2: eine Datei in das aktuelle Verzeichnis kopieren
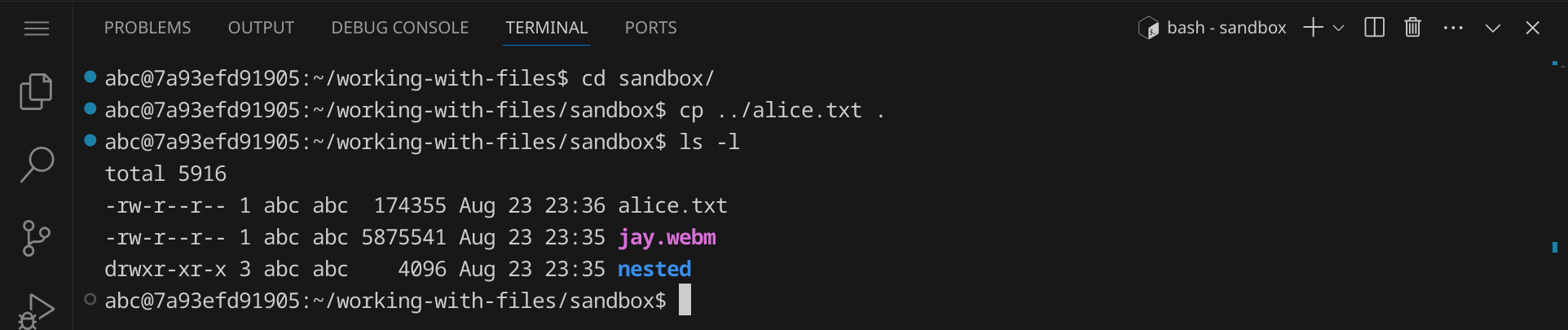
Geh in das Verzeichnis sandbox und kopiere die Datei alice.txt hinein:
cd sandbox cp ../alice.txt .
. steht für das aktuelle Verzeichnis. Wenn du also eine Datei in das aktuelle Verzeichnis kopieren möchtest, kannst du den Punkt als Ziel angeben.
Die Datei alice.txt wurde ebenfalls in das Verzeichnis sandbox kopiert:
Wenn du versuchst, ein Verzeichnis zu kopieren, erhältst du eine Fehlermeldung:
cp ../zork-master .

Um ein Verzeichnis zu kopieren, musst du die Option -r (für »recursive«) verwenden:
cp -r ../zork-master .
Das Verzeichnis zork-master wurde in das Verzeichnis sandbox kopiert:
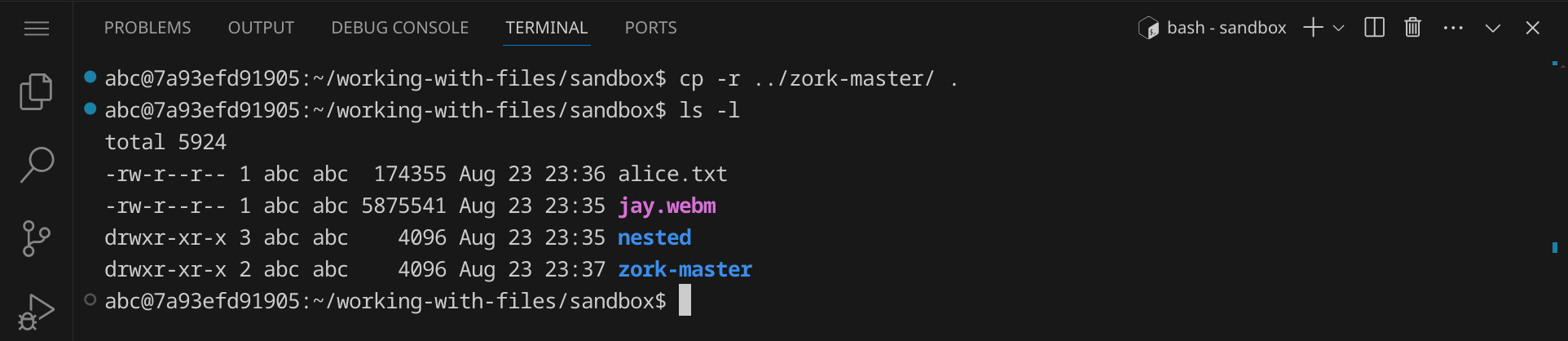
Nutze den Befehl mv, um Dateien und Verzeichnisse zu verschieben. Der Befehl mv benötigt ebenfalls zwei Argumente: die Quelle und das Ziel. Der Unterschied zu cp besteht darin, dass mv die Datei oder das Verzeichnis an den neuen Speicherort verschiebt, während cp eine Kopie erstellt. Verschiebe die Datei jay.webm in das Verzeichnis nested:
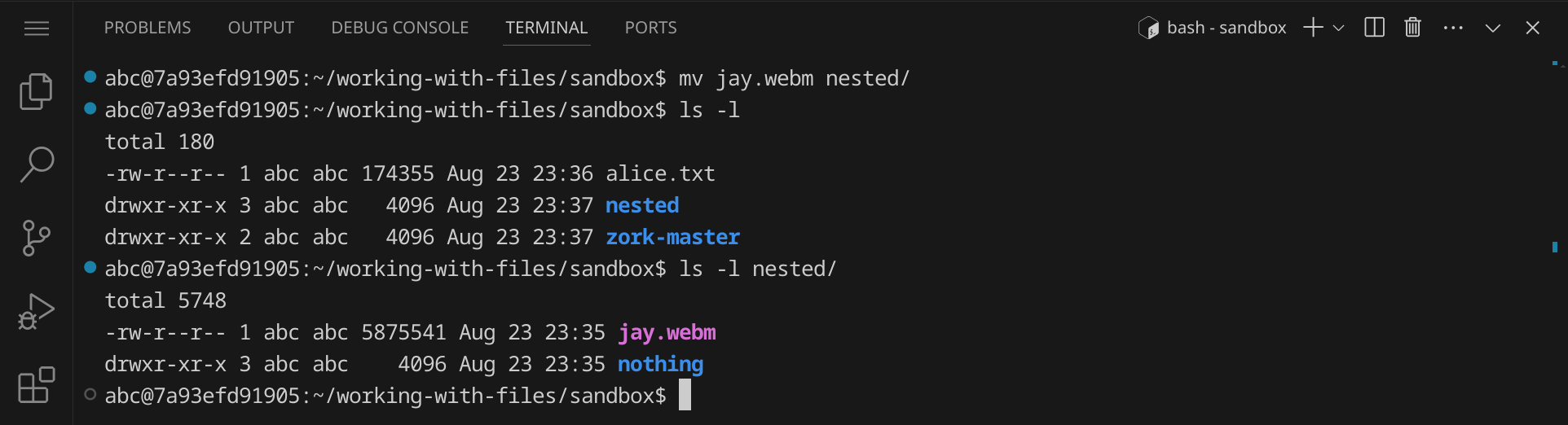
mv jay.webm nested
Du siehst nun, dass die Datei jay.webm nicht mehr im Verzeichnis sandbox ist, sondern im Verzeichnis sandbox/nested:
Du kannst mv auch verwenden, um Dateien umzubenennen. Versuche, die Datei alice.txt in alice-in-wonderland.txt umzubenennen:
mv alice.txt alice-in-wonderland.txt
Du siehst nun, dass die Datei alice.txt in alice-in-wonderland.txt umbenannt wurde:

Nutze den Befehl rmdir, um ein leeres Verzeichnis zu löschen. Der Befehl rmdir löscht nur leere Verzeichnisse. Bevor wir diesen Befehl testen können, legen wir uns ein leeres Verzeichnis namens empty an:
mkdir empty
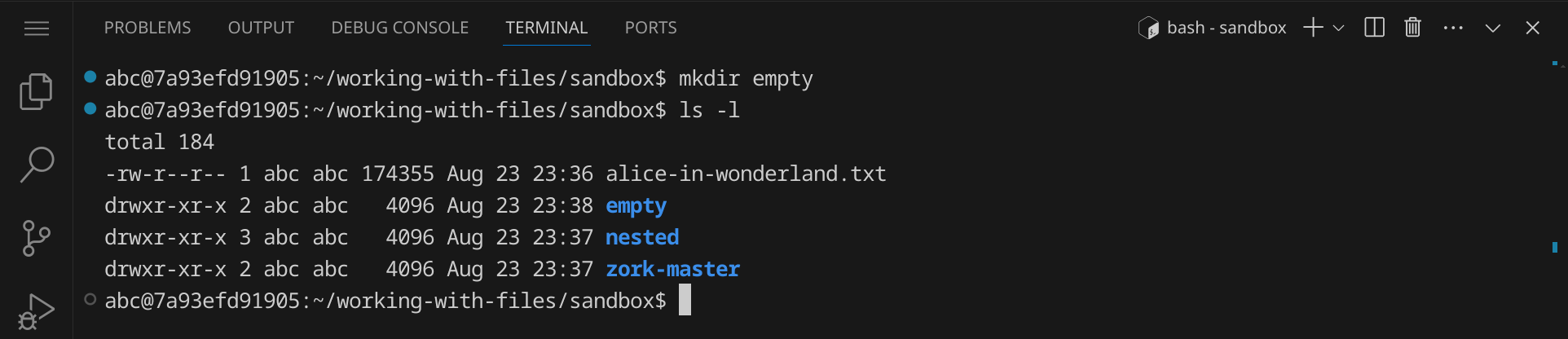
Nutze rmdir, um das Verzeichnis empty zu löschen:
rmdir empty
Wie du sehen kannst, ist das Verzeichnis empty nicht mehr vorhanden:

Versuche, das Verzeichnis zork-master mit rmdir zu löschen:
rmdir zork-master
Erwartungsgemäß erhältst du eine Fehlermeldung, da das Verzeichnis nicht leer ist:

Du kannst rmdir also dann nutzen, wenn du ein Verzeichnis löschen möchtest, von dem du ausgehst, dass es leer ist. Falls das Verzeichnis doch nicht leer sein sollte, erhältst du eine Fehlermeldung.
Nutze den Befehl rm, um Dateien und Verzeichnisse zu löschen. Der Befehl rm benötigt ein Argument: die Datei oder das Verzeichnis, das gelöscht werden soll.
rm löscht Dateien und Verzeichnisse dauerhaft, ohne sie in den Papierkorb zu verschieben. Das Konzept des Papierkorbs gibt es im Terminal nicht. Sei also vorsichtig, wenn du rm verwendest, und überlege dir gut, ob du wirklich Dateien oder Verzeichnisse löschen möchtest.
Lösche die Datei alice-in-wonderland.txt:
rm alice-in-wonderland.txt
Die Datei alice-in-wonderland.txt wurde gelöscht:

Wenn du versuchst, ein Verzeichnis zu löschen, musst du wie bei cp die Option -r (für »recursive«) verwenden:
rm -r zork-master

In diesem Kapitel hast du gelernt, wie du im Terminal mit Dateien und Verzeichnissen arbeiten kannst. Du hast gesehen, wie du Dateien und Verzeichnisse erstellen, bearbeiten, analysieren, durchsuchen, filtern, komprimieren, extrahieren, kopieren, verschieben und löschen kannst. Du hast auch gelernt, wie du Dateien und Verzeichnisse analysieren und durchsuchen kannst. Du hast die wichtigsten Befehle kennengelernt, die du benötigst, um effizient mit Dateien und Verzeichnissen im Terminal zu arbeiten.